
Table of Contents
Last update: June 2026. All opinions are my own.
ML Foundations · Post 2/10
The first big idea
This is the single most important sentence in the entire course. Write it down.
🔑 IT'S GENERALIZATION THAT COUNTS.
Imagine you build a model to predict customer churn and it achieves 99% accuracy. Are you done? Not yet — you don't know how good the model is until it sees data it has never seen before. You don't care about predicting the past; you care about predicting the future.
Generalization is how well your model behaves on data it hasn't seen. And it's difficult — because all you ever have is past data.
The wealth-vs-happiness example
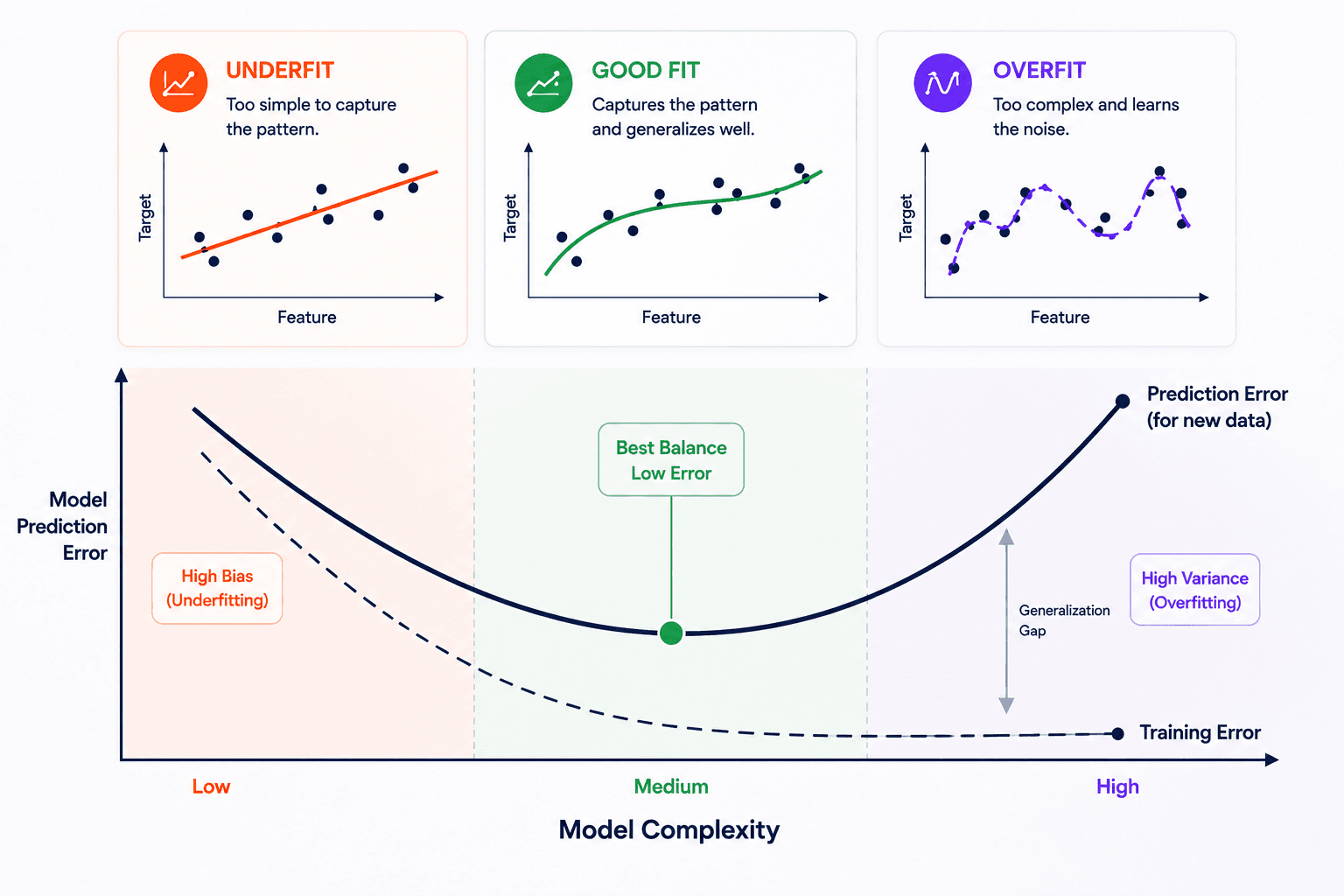
You're trying to predict someone's happiness from their wealth. You have a scatter plot. You try three models:
- A linear model — a straight line through the data. Goes roughly in the right direction but misses obvious structure. Training error high, test error high. This is underfitting: the model is too simple.
- A quadratic model — a gentle curve. Captures the bulk of the pattern. Training error drops. Test error drops. Good fit.
- A complex model — the curve snakes through every point. Training error is essentially zero. But it's memorised the noise. On a new data point, the prediction is wild. The training error is 0; the test error is huge. This is overfitting.
You can always reduce training error by making the model more complex. That's a one-way knob. But test error is U-shaped: it goes down at first, hits a minimum, then climbs as the model starts memorising noise instead of pattern. The bottom of that U is the sweet spot.
Underfitting vs overfitting in one line
- Underfit: high training error, high test error. Too rigid to capture the pattern.
- Overfit: near-zero training error, high test error. Has learned the training data instead of the underlying pattern.
The whole game is to find the sweet spot in the middle.
Cross-validation, in one sentence
The practical tool for finding that sweet spot:
Randomly divide your training data into k subsets, hold out each one in turn while training on the rest, test the model on the held-out one, average the k scores.
This gives a much more honest estimate of how the model will perform on truly unseen data — you're testing on data you didn't train on, and averaging over k splits so you don't get tricked by a lucky one. Cross-validation is the way you evaluate any ML model in practice.
💡 Practical note: the larger your dataset and the smarter your feature engineering, the less you have to worry about overfitting. Big datasets give the model enough signal that the noise can't dominate. A few thousand examples? Worry. A few million? Less worry.
Next up — Post 3: The Curse of Dimensionality.