
Table of Contents
Last update: June 2026. All opinions are my own.
ML Foundations · Post 8/10
There are six failure modes that account for almost every ML project that goes sideways. Four are about the data. Two are about the model. The data ones are the more common.
1. Insufficient data
The single most common reason an ML model doesn't work: there isn't enough of it. Modern algorithms — especially deep learning — need thousands to millions of examples to learn anything useful.
The fix: collect more, augment what you have (image rotations, synonym substitutions, simulation), or use a simpler model that needs less data.
2. Non-representative training data
Your training data has to look like the data you'll see in production. Train on people from one country and deploy globally — you'll get systematic errors on every other country. Train on photos taken in daylight and deploy on security cameras at night — same problem.
Common variants:
- Sampling bias. The sampling method itself favours certain cases (survey respondents are wealthier on average than non-respondents).
- Drift. The world changes between when you collected data and when the model runs (pre-pandemic shopping data, deployed in 2021).
3. Poor quality data
Noisy, missing, inconsistent, or incorrect values. Outliers caused by data-entry mistakes. Columns recorded in different units across rows. Every minute spent fixing these pays for itself many times over downstream.
4. Irrelevant features
Even with plenty of clean, representative data, irrelevant features make learning harder. The model has to figure out which dimensions matter and which are noise — and as the curse of dimensionality post showed, that gets exponentially harder with each useless feature.
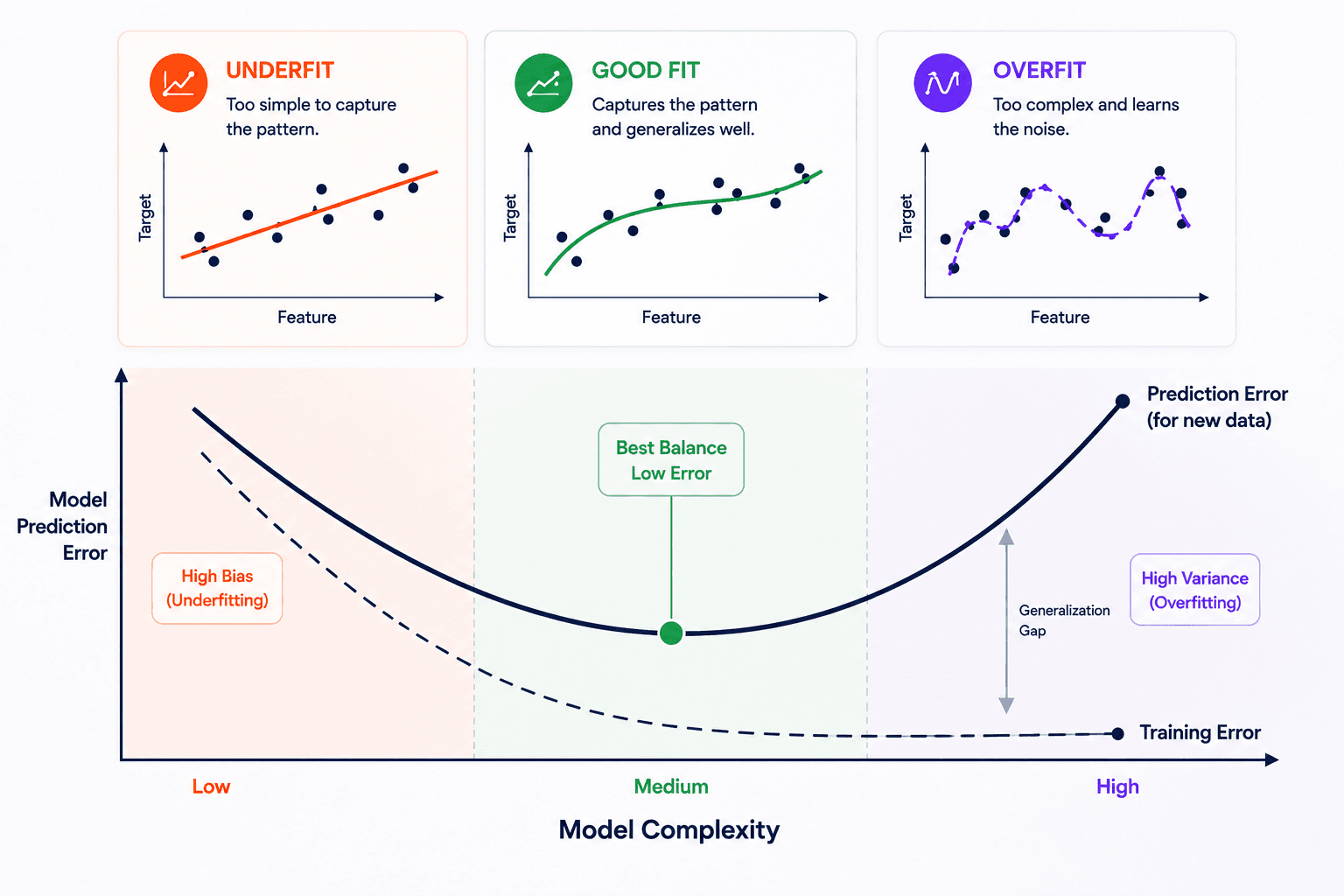
5. Overfitting
The model has memorised the training data, including its noise. Training error is near zero; test error is much higher. The model knows what already happened — it can't predict what's next.
The fixes: more data, simpler models, regularisation, cross-validation to detect it, and being honest about the gap between training and test scores.
6. Underfitting
The opposite failure: the model is too simple to capture the pattern. Training error and test error are both high. A linear model on a U-shaped pattern. A shallow tree on a problem that needs deep splits.
The fix: more flexible representation, more features, or features that encode the non-linearity the model can't see on its own.
⭐ Better data, better features, and the right model lead to better generalization. Almost everything else is detail.