
Table of Contents
Last update: June 2026. All opinions are my own.
ML Foundations · Post 10/10
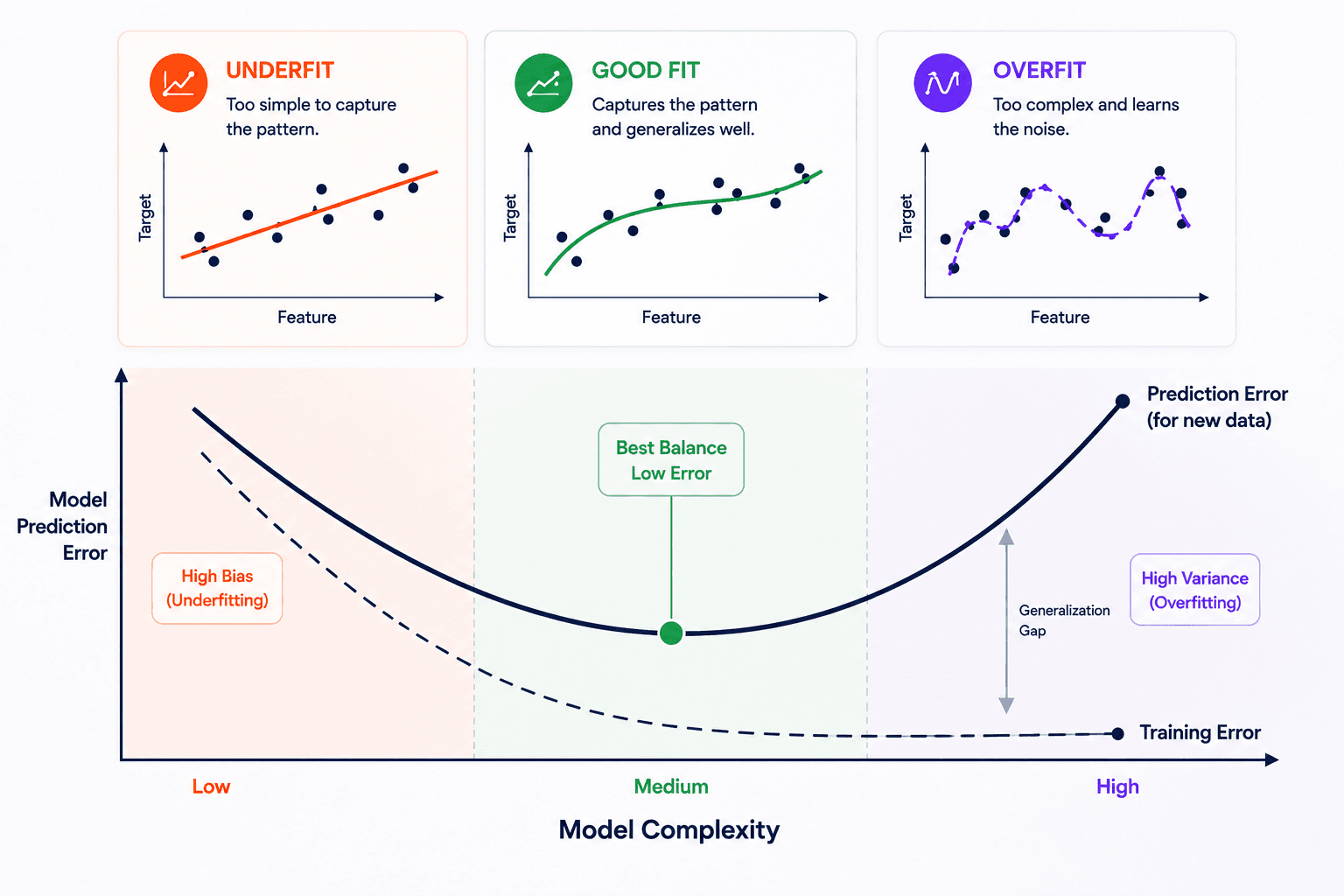
You've picked a model, engineered features, and care about the right metric. One question remains: how do you actually pick a configuration of the model, and how do you know how well it'll do on data it has never seen?
Train / Validation / Test split
Split your data into three disjoint sets:
- Train (60–70%) — fit the model parameters.
- Validation (15–20%) — pick the model, pick the hyperparameters. Used many times during development.
- Test (15–20%) — final unbiased evaluation. Used once, at the end.
The whole reason for three splits instead of two: every time you make a decision based on the validation score, the validation set becomes a little less of an honest measure. After dozens of comparisons, the validation score is also overfit. The test set, used exactly once, is the unbiased number you report.
⚠️ Never tune on the test set. It must remain unseen until the very end. If you check the test score and then go back to change anything, the test set is contaminated and the final number is no longer trustworthy.
Cross-validation (k-fold)
For small datasets, a single validation split is wasteful and noisy. k-fold cross-validation rotates the validation set:
- Split the training data into k equal folds.
- Train on k−1 folds, validate on the remaining one.
- Repeat k times, each fold playing the validation role once.
- Average the k scores.
You get k validation scores instead of one — and every training example gets used for both training and validation across the folds. Standard k values: 5 or 10. Stratified k-fold preserves the class balance in each fold, useful for imbalanced classification.
Estimators in scikit-learn
The whole loop fits into a tiny API. Every model in scikit-learn shares the same three methods:
model.fit(X_train, y_train) # learn parameters
preds = model.predict(X_test) # predict on new data
score = model.score(X_test, y_test) # default metric for the modelFor hyperparameter tuning, GridSearchCV and RandomizedSearchCV wrap any estimator and run cross-validation across a grid of parameter combinations, returning the best one. You write the parameter grid once and let it explore.
The discipline
The whole machinery exists for one reason: keeping your final number honest. If at any point the test set leaks into your decisions — even indirectly, by peeking at it and then "just trying one more thing" — the number you report stops being a prediction and starts being a description of the data you already saw.
The model picking, the tuning, the cross-validation, the careful split: all of it is just bookkeeping to make sure the final test score answers the question you actually care about — will this model work on data it has never seen?
That's the last of the foundations. From here, every algorithm-specific deep dive in the rest of the series rests on these ten ideas.