
Table of Contents
Last update: June 2026. All opinions are my own.
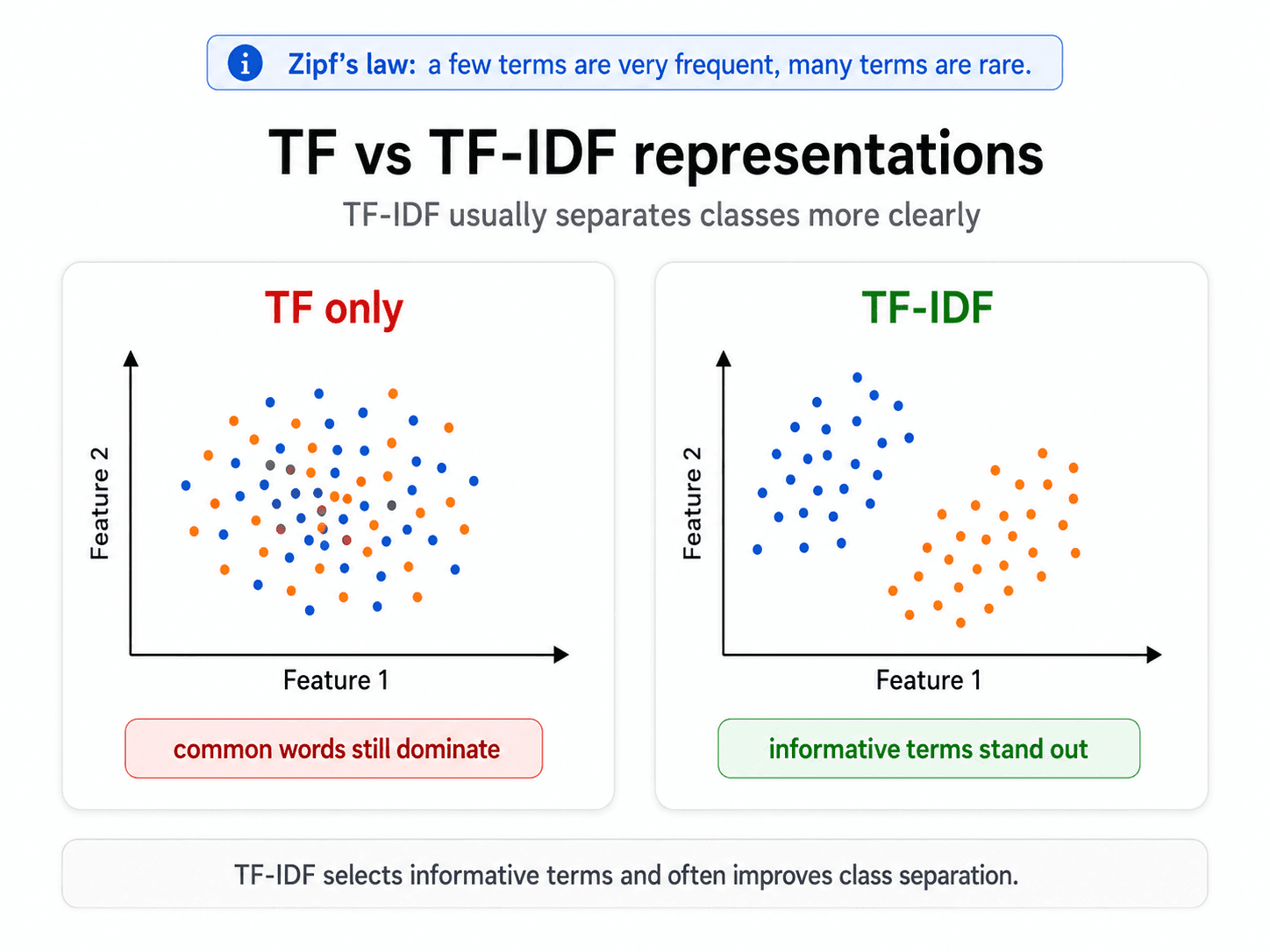
A small exploration to make TF-IDF concrete. I built a tiny six-document corpus by hand, ran two vectorisers over it, and looked at what each one thinks the most important words are.
"TF-IDF down-weights common words and up-weights rare ones." — every NLP tutorial ever
I'd read the sentence a hundred times. I had the formula memorised. I'd implemented it from scratch in an assignment. But I'd never actually looked at what changes between a raw count matrix and a TF-IDF matrix on the same corpus. So I built one.
💻 Run it yourself — open the notebook in Colab ↗. No install needed — scikit-learn ships with Colab. The whole thing runs in under 30 seconds.
The setup
Six short documents. Two about machine learning, two about cooking, two about gardening. I picked them so the topic vocabulary would be obvious but the function words (the, is, and) would still dominate raw counts.
corpus = [
"The neural network learns by adjusting its weights through backpropagation.",
"A deep neural network with many layers can model complex patterns.",
"Heat the butter in a pan and gently fry the onions until soft.",
"Boil the pasta in salted water until al dente, then drain.",
"Water the tomato plants in the morning to avoid mildew on the leaves.",
"Prune the rose bushes in early spring before new growth appears.",
]CountVectorizer first
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X_count = cv.fit_transform(corpus)
vocab = cv.get_feature_names_out()Now look at the top 5 words per document by raw count:
Doc 1 (ML): the, network, neural, by, its
Doc 2 (ML): network, can, complex, deep, layers
Doc 3 (cooking): the, and, butter, fry, gently
Doc 4 (cooking): the, in, al, boil, dente
Doc 5 (gardening):the, in, on, plants, tomato
Doc 6 (gardening):the, in, before, bushes, earlyFive out of six documents have "the" in their top words. If I tried to compute similarity on this matrix, the documents would mostly look alike because they all contain "the" a lot. That's the failure mode the whole post is about.
TfidfVectorizer
Same corpus, same tokenization, same vocabulary. Different weights.
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer()
X_tfidf = tv.fit_transform(corpus)Top 5 words per document, now by TF-IDF weight:
Doc 1 (ML): backpropagation, adjusting, weights, learns, neural
Doc 2 (ML): layers, complex, model, deep, patterns
Doc 3 (cooking): butter, gently, fry, onions, soft
Doc 4 (cooking): pasta, dente, drain, salted, al
Doc 5 (gardening):tomato, mildew, plants, leaves, morning
Doc 6 (gardening):bushes, prune, rose, growth, springNo "the." No "is." No "in." Every top word is something the document is actually about. The two ML docs read as ML. The two cooking docs read as cooking. The two gardening docs read as gardening. And nobody told the model what a "topic" was. It just looked at frequencies.
That's TF-IDF doing its job. The math from Part 2 — multiply by log(N / df), words that appear in every document get a multiplier of zero — translates directly into "the" disappearing from the top of every list.
Cosine vs Euclidean — the long-book trap, concretely
The second thing I wanted to verify: the long-book / short-book trap. Same idea, smaller scale.
I made one of the cooking documents artificially long by repeating it. Same content, just more of it.
corpus_with_long_doc = corpus + [
corpus[2] * 20, # the buttery-onion sentence, 20× longer
]Then I computed pairwise distances both ways:
Euclidean distance:
short cooking ↔ short ML: 4.1
short cooking ↔ long cooking: 27.6 ← far apart!
long cooking ↔ short ML: 28.0
Cosine distance:
short cooking ↔ short ML: 0.97 ← far (different topic) ✓
short cooking ↔ long cooking: 0.00 ← identical (same topic) ✓
long cooking ↔ short ML: 0.97 ← far (different topic) ✓Under Euclidean, the long cooking doc is closer to the short ML doc than to its own short version. Under cosine, the two cooking docs collapse to distance zero — which is what you want. Length isn't topic.
What I'd do differently
Three things I noticed while writing this:
- The corpus needs to be small enough to read. I tried 50 docs at first and the output was unreadable. Six is the right size for an explainer.
- Don't lowercase / remove stop words first. That hides what TF-IDF is doing. The whole point is to show TF-IDF crushing "the" automatically, which means "the" has to be in the matrix.
- TF-IDF isn't magic. If the corpus is small and homogeneous (all six documents about cooking), TF-IDF still down-weights cooking-specific terms because they appear in every document. The math is doing exactly what the formula says — there's no semantic understanding underneath.
The big thing I learned isn't about the libraries. It's that TF-IDF is the simplest possible upgrade over raw counts, and it changes the output more than I would have guessed. Before reaching for any neural model, this is the baseline I'd want to beat.