
Table of Contents
Last update: June 2026. All opinions are my own.
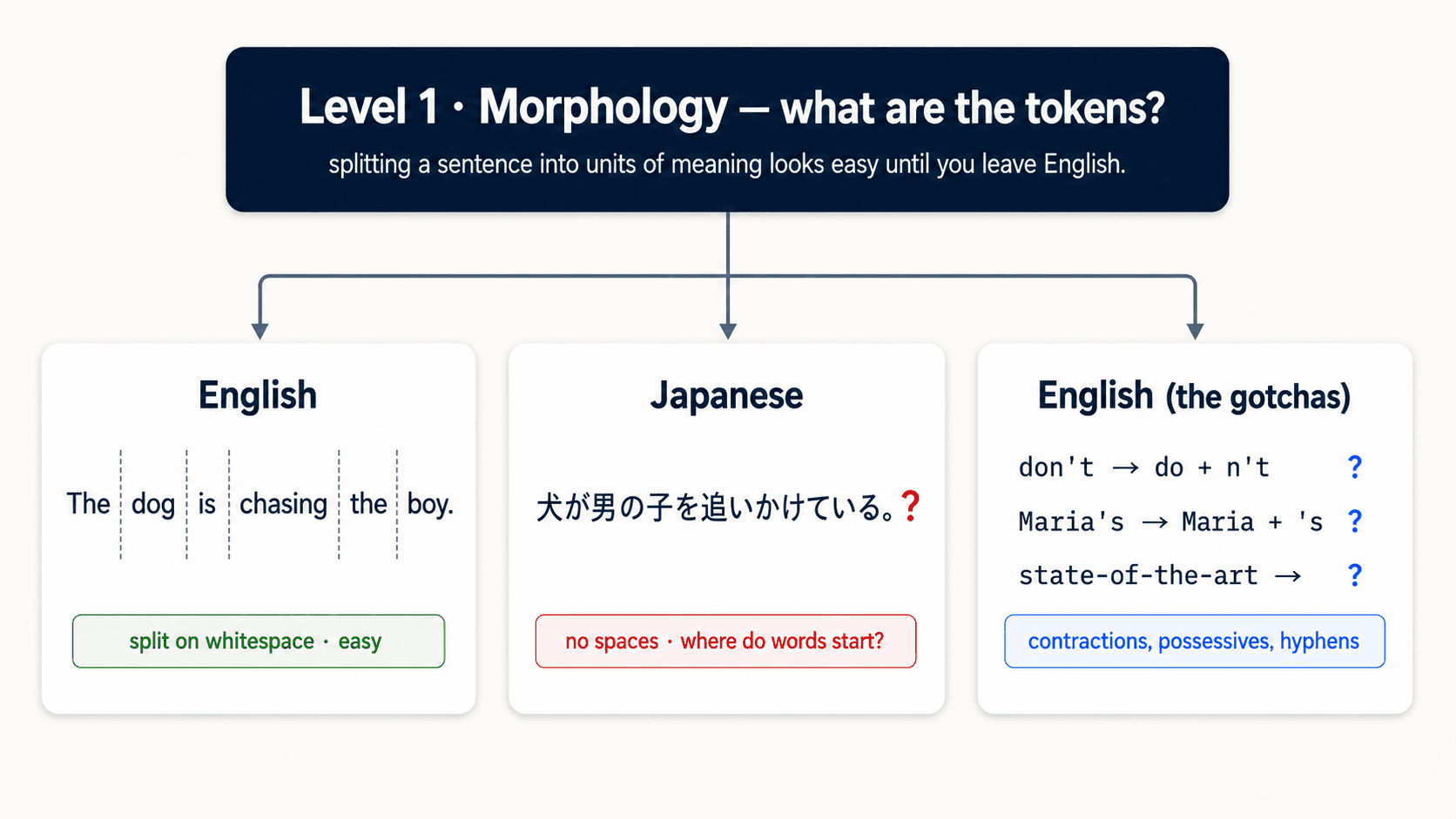
A small exploration of two of the most common English tokenizers in Python — and what their disagreement says about the assumption that "splitting a sentence into words" is a solved problem.
"How hard can it be to split a sentence into words?" — me, before I actually tried
I'd been reading about NLP and I had this comfortable belief that tokenization is the easy part. You split on whitespace, you peel off punctuation, you're done. Move on to the interesting stuff.
Then I gave the same sentence to two libraries and they gave me back two different word lists.
The setup
💻 Run it yourself — open the notebook in Colab ↗. No install needed. The first cell takes ~30s to set up nltk + spaCy + the English model, then everything below runs in seconds.
import nltk
import spacy
nltk.download("punkt_tab", quiet=True)
nlp = spacy.load("en_core_web_sm")
sentence = "She's reading the state-of-the-art paper. Don't tell her it's mine."
nltk_tokens = nltk.word_tokenize(sentence)
spacy_tokens = [t.text for t in nlp(sentence)]Same sentence, two libraries, two list[str] outputs. They should agree, right?
They don't
They agree on the easy parts — reading, the, paper, tell, her, mine — fine. But every interesting word causes friction:
- Contractions —
She's→ both split it, but they label the pieces differently and put them in different places downstream. Same forDon't,it's. - Hyphenated compounds —
state-of-the-artstays as one token in some versions, splits into seven in others (state,-,of,-,the,-,art). The decision is buried in infix rules that change between minor versions of the library. - Punctuation around contractions — "Don't tell her it's mine." — does the final period sit next to
mineasmine.or does it get its own token? Depends on the tokenizer's punctuation policy.
The point isn't that one library is wrong. It's that "split this sentence into words" is not a well-defined task. Both libraries are answering a slightly different question.
Why they disagree
The two tokenizers come from different philosophies:
- nltk's
word_tokenizeuses the Penn Treebank convention — a set of rules baked into linguistic-corpus work from the 90s. The rules are deterministic, well-documented, and decades-old. Whatever the Penn Treebank corpus did, this tokenizer does. Reproducible, predictable, conservative. - spaCy's default English tokenizer is a rule-based pipeline of prefixes, suffixes, infixes, and special cases, tuned for downstream model performance. The rules get updated when a downstream task benefits from a different split. Less predictable across versions, more useful for modern pipelines.
Neither one is "right." They're optimised for different ends. nltk is optimised for matching a historical corpus convention. spaCy is optimised for feeding into a transformer.
What this means in practice
The pipeline-level lesson: pick the tokenizer that matches what comes next, not the one you've heard of.
| If your downstream is… | Use |
|---|---|
| A linguistics-class assignment, or matching Penn Treebank annotations | nltk |
| A spaCy-based pipeline (NER, POS tagging, parsing) | spaCy |
| A transformer (BERT, RoBERTa, GPT-style) | The model's own tokenizer (AutoTokenizer.from_pretrained(...)) — BPE, WordPiece, or SentencePiece, not either of these |
| Search / IR / keyword extraction | Whatever your indexer expects, which is probably its own thing |
The tokenizer is part of the model contract. Mix them and you get silent quality drops — the model sees state-of-the-art and state, -, of, -, the, -, art as different inputs, but you don't realise because the code doesn't error.
The surface vs the cliff
This is the English version of the problem. English has spaces. Even with spaces, two well-respected tokenizers disagree on a 13-word sentence.
Japanese doesn't have spaces. Chinese doesn't have spaces. Thai doesn't have spaces. Tokenizing those languages requires a learned model — not a rule-based splitter — because there's no obvious place where a word ends and the next one begins. The disagreement on state-of-the-art is the easy version.
What I'd do differently
If I ran this again, I'd:
- Pin the tokenizer version in
requirements.txt. Infix rules change between releases — the outputs above are tied to specific versions of nltk and spaCy. - Write the comparison as a small test, not a script. Set the expected outputs and let CI tell me when a library upgrade changes the tokenization.
- Always check the tokenizer that comes with the model, before assuming nltk or spaCy is good enough. For anything transformer-based, those two are irrelevant.
The bigger thing I learned isn't about the libraries. It's that the question "what is a word?" doesn't have a single answer, and the moment you accept that, everything in NLP gets a little easier to reason about. There is no canonical layer 1. It depends on what layer 2 is going to do with it.