Page 1 · Foundations
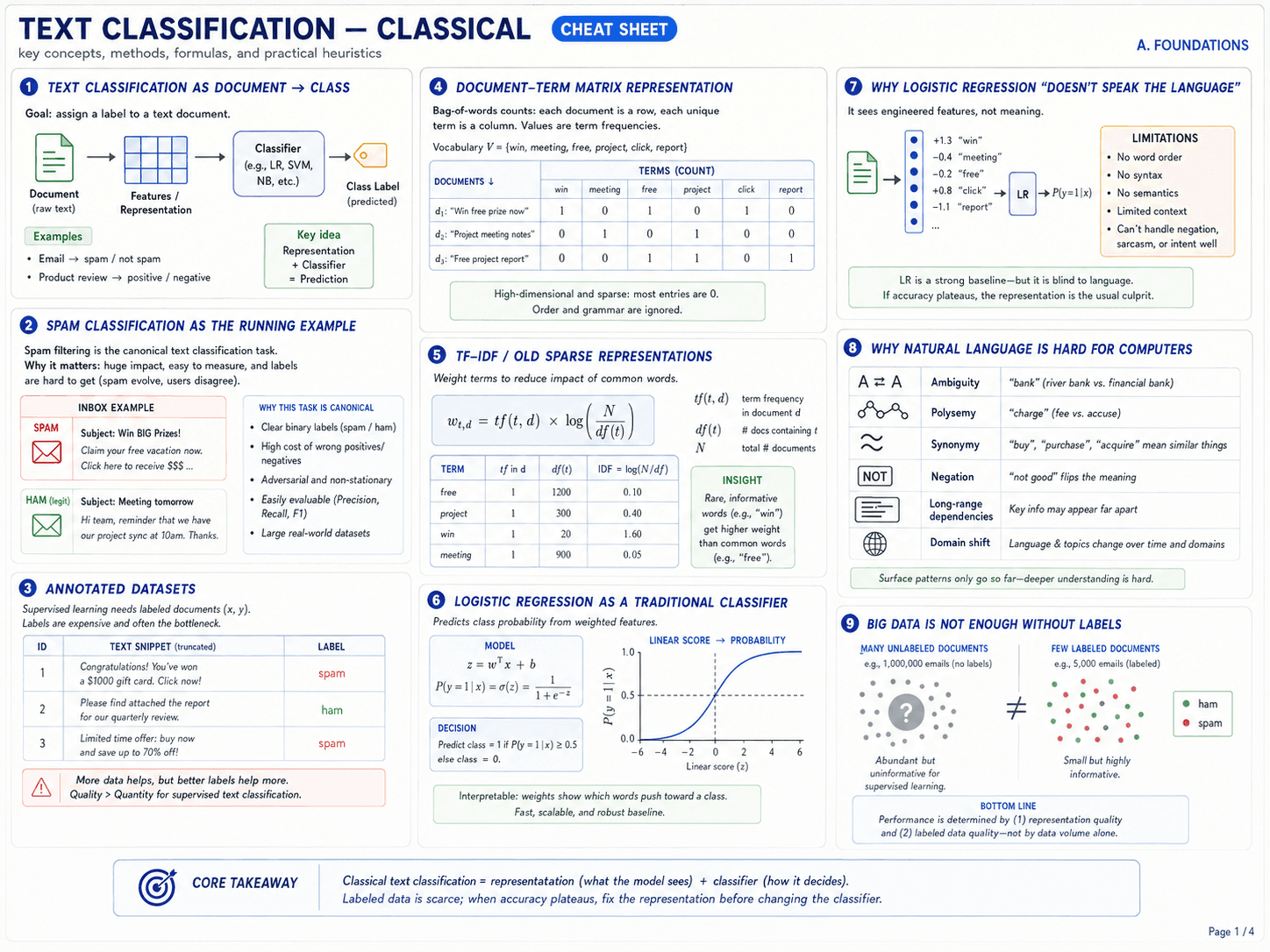
Page 2 · Applications
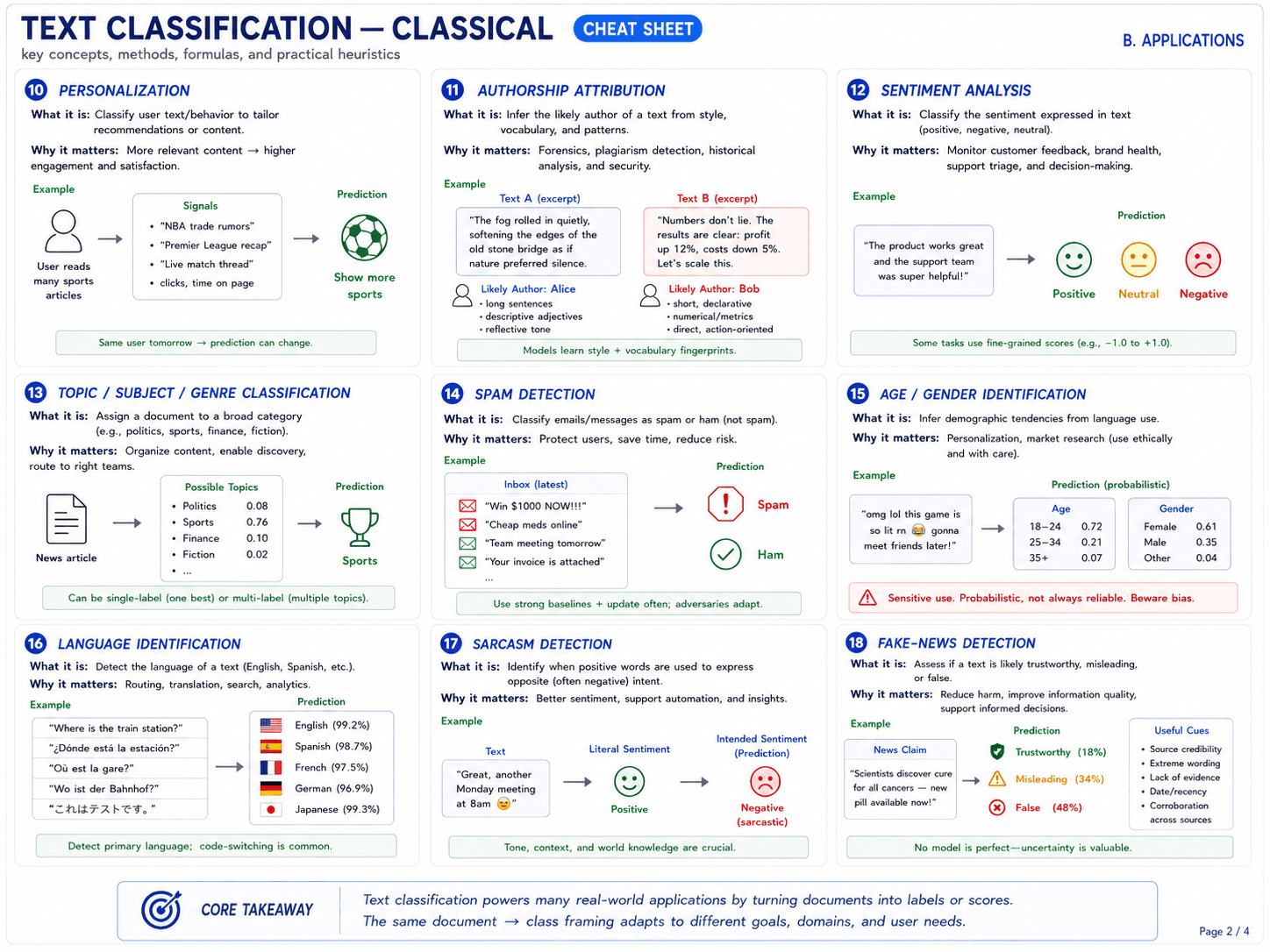
Page 3 · Classical methodologies I
![Page 3 of 4 — Classical methodologies I. Eight cards (19–26): (19) hand-coded / rule-based systems, expert-written if-then patterns and keyword rules, example: IF has 'free' AND has 'win' → spam, good for high-precision/safety-critical/domain-specific patterns, expensive to maintain; (20) supervised machine learning formulation, learn a function f(x) from labeled examples (x,y) to predict labels for new documents, pipeline: labeled documents → features representation (bag-of-words, TF-IDF) → learned classifier (NB, MaxEnt, LogReg, SVM) → predicted class, goal: minimize generalization error on unseen documents; (21) Naïve Bayes, probabilistic classifier using word evidence with Bayes' rule and conditional independence assumptions, intuition: bag-of-words document 'free prize click now' with order ignored, multiplies word likelihoods under each class and combines with prior to get posterior, strong with many features, sensitive to rare words (use smoothing); (22) Bayes formula: prior, likelihood, posterior, marginal, P(class | words) = P(words | class) P(class) / P(words), four labeled components: P(class|words) Posterior (what we want), P(words|class) Likelihood, P(class) Prior, P(words) Marginal (normalizer), decision rule: choose class with highest posterior; (23) Naïve Bayes independence assumption, words are assumed conditionally independent given the class, true (complex) graph shows dependent words like 'free' and 'prize', naïve simplified graph assumes independence P(w_1, ..., w_n | c) = product of P(w_i | c), often unrealistic but usually works very well in practice; (24) MaxEnt classifiers, Maximum Entropy / log-linear models use weighted features and softmax to produce class probabilities, more expressive than NB, integrates diverse features, example weights: bias (always 1) +0.20, has 'free' +1.30, has 'meeting' -1.00, starts with 're:' -0.60, all-caps > 2 +0.25, length > 100 +0.15, softmax: P(c|x) = exp(s_c(x)) / sum_c' exp(s_c'(x)); (25) MaxEnt constraints, the learned model matches the expected feature values observed in training data, E_model[f_j | c] = E_data[f_j | c], example: has 'free' for spam training 0.42 and model 0.42 ✓, has 'meeting' for spam training 0.08 and model 0.08 ✓, guarantees the model respects what we know from data; (26) maximum entropy = most uniform model, among all models that satisfy the constraints, pick the one with maximum entropy (least committed/most uniform), H(P) = -sum_x P(x) log P(x), MaxEnt ⇒ least biased model consistent with what we know. Core takeaway: we progress from manual rules (interpretable) → supervised learning (automatic) → probabilistic models (principled uncertainty); Naïve Bayes makes strong independence simplifications; Maximum Entropy relaxes them using features, constraints, and maximum entropy.](/_next/image?url=%2Fimages%2Fblog%2Fnlp-from-scratch%2Ftext-classification%2Fcheatsheet%2Fpart-6-page-3-methodologies-1.png&w=3840&q=75)
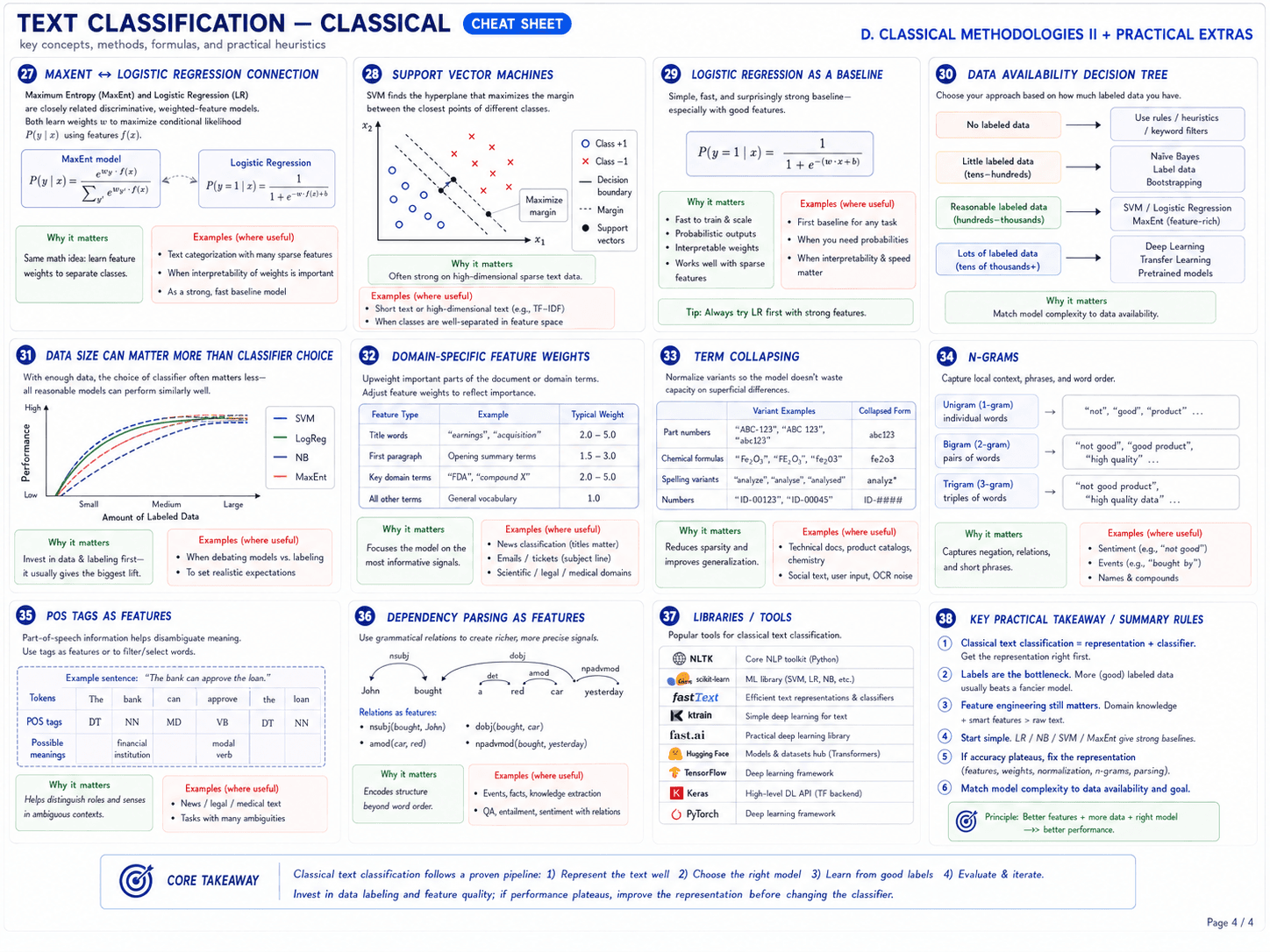
Page 4 · Classical methodologies II + practical extras
Cheat sheet
Four illustrated pages — foundations, applications, the four classical methodologies, and the practitioner rules.

Or read the searchable version below.