
Last update: June 2026. All opinions are my own.
ML Foundations · Post 1/10
A machine that "learns"
A machine learning algorithm is, in the most literal sense, a piece of code that gives computers the ability to learn. The textbook definition is Tom Mitchell's, and it's still the cleanest formulation anyone has come up with:
A computer program learns from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Three ingredients: a task, experience, a way to measure how it's going. The classic example is a spam filter:
- Task (T): flag emails as spam or not spam.
- Experience (E): the emails users have already flagged.
- Performance measure (P): the percentage of emails it gets right.
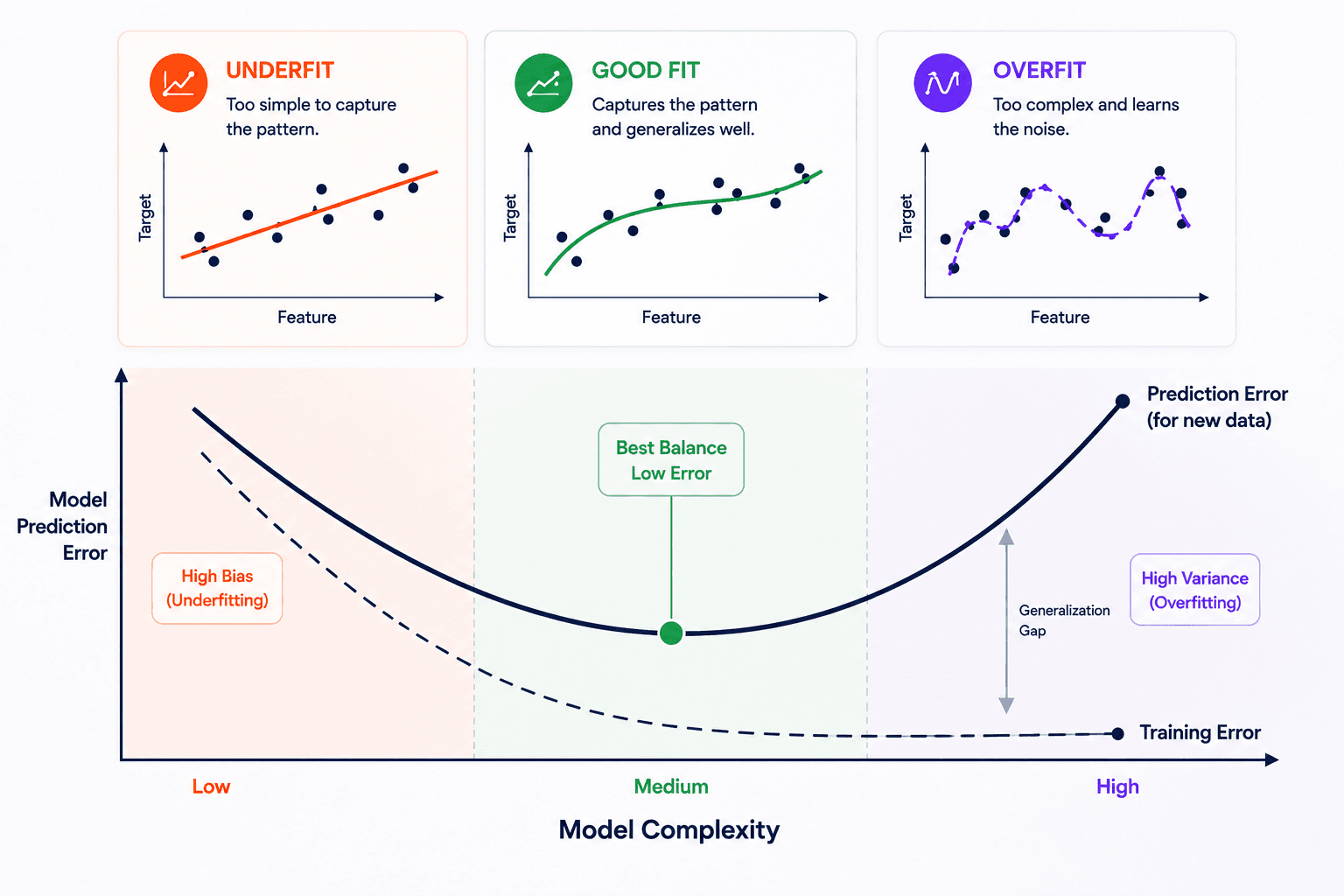
If, the more flagged examples it sees, the better it gets at classifying — that's learning.
💡 Heuristic that's saved me hours: only implement ML if the solution genuinely is machine learning. A rule-based system is faster to build, easier to debug, and won't drift on you. Reach for ML when the rules are too many, too fuzzy, or unknown.
Learning = Representation + Evaluation + Optimization
Every ML algorithm — every single one — decomposes into three pieces. This framing comes from Pedro Domingos's "A Few Useful Things to Know About Machine Learning" paper, and it's the lens I use to compare algorithms.
1. Representation
The first thing every algorithm picks is what kind of solution it can express. A linear regression can only fit a straight line. A decision tree can only carve the space into axis-aligned boxes. A neural network can express almost anything — at the cost of needing huge amounts of data and being basically uninterpretable.
In plain terms: you pick the shape of the model first, then training finds the best version of that shape.
2. Evaluation
You have a model. How do you know it's any good? You need a metric — accuracy, F1, RMSE, whatever fits the problem. The metric you pick is the thing your model will optimise for, so picking the wrong metric means optimising the wrong thing. Accuracy isn't always the right answer, and on imbalanced data it's actively misleading.
3. Optimization
How does the algorithm actually search through the hypothesis space to find the best one? Gradient descent, tree splitting, dual quadratic programming — every algorithm has its own. The internals matter for advanced use but the foundations don't dwell.
For now: representation chooses the shape, evaluation chooses the goal, optimization does the searching.
Next up — Post 2: Why Generalization Matters More Than Training Accuracy.