
Last update: June 2026. All opinions are my own.
ML Foundations · Post 6/10
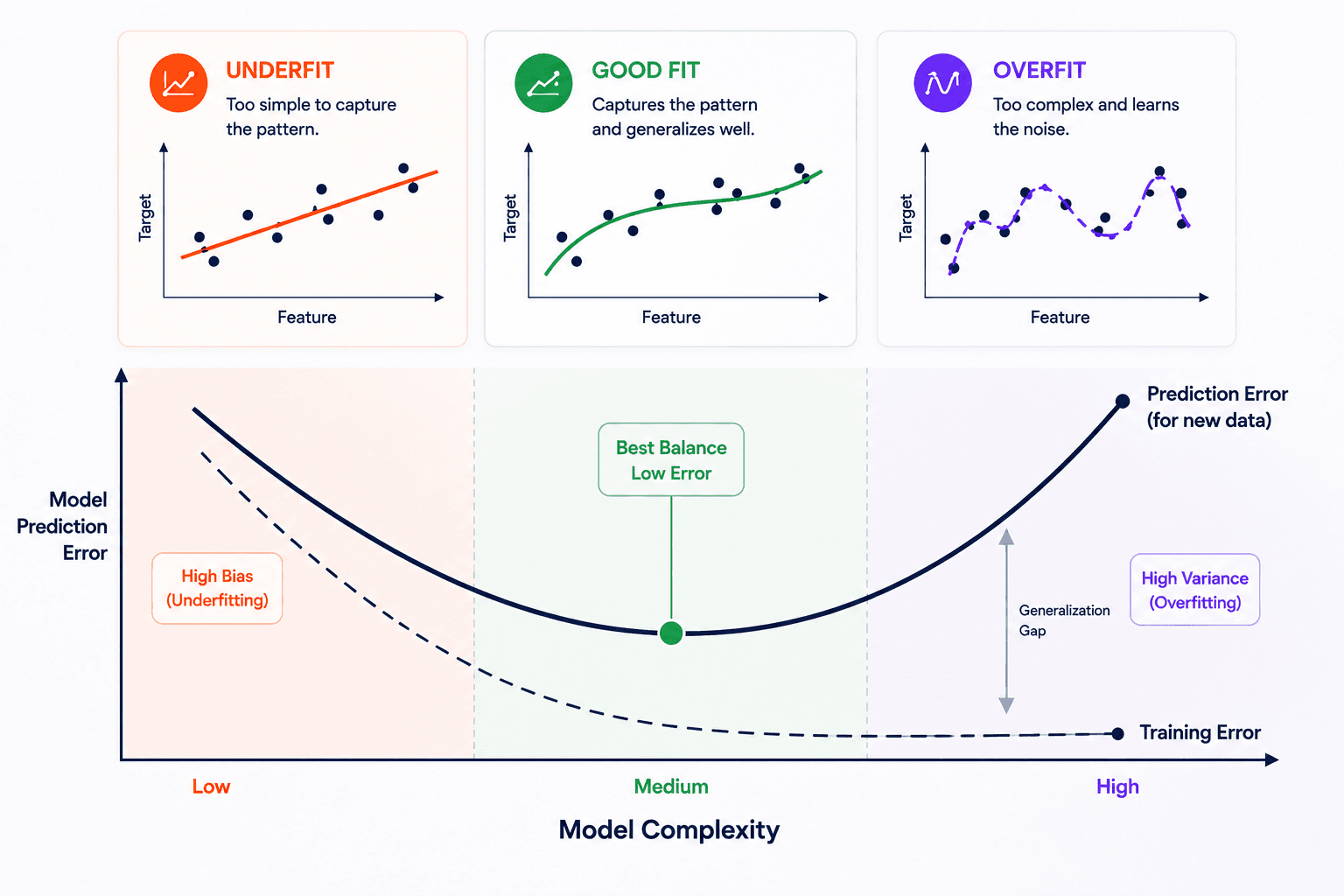
No single best algorithm
The No Free Lunch theorem says, informally: there is no single algorithm that's best for every problem. Averaged across all possible problems, every algorithm performs the same. The reason a particular algorithm wins on a particular dataset is that the dataset has structure the algorithm's representation happens to fit.
This sounds like bad news. It's actually freeing — it tells you to stop hunting for the algorithm and start picking the right one for the problem in front of you.
And it gives you a stronger practical move: don't pick one model. Train several. Combine them.
The ensemble decision boundary
Imagine three different models trained on the same data:
- Model A — a decision tree. Carves the space into rectangles. Misses smooth curves but nails the categorical cuts.
- Model B — a logistic regression. Smooth linear boundary. Misses non-linear regions but gets the broad direction right.
- Model C — a KNN. Local, jagged. Gets the local pockets right but is noisy in sparse regions.
Each is wrong in a different way. Each model's errors are roughly independent of the others'.
Average their predictions and the independent errors cancel out — while the signal that all three agree on reinforces. The combined decision boundary captures what every individual model gets right, without being held back by where each one fails.
Ensemble methods
The foundations land you in front of four major ensemble strategies, each a different way to combine many models:
- Random Forest — a forest of decision trees, each trained on a random subset of data and features. Averaged at the end. The canonical example of why ensembles work.
- Bagging (Bootstrap Aggregating) — train each model on a different random sample (with replacement). Reduces variance.
- Boosting — train models sequentially, each one focusing on the examples the previous ones got wrong. Reduces bias. XGBoost is here.
- Stacking — train models, then train a meta-model that learns how to combine their predictions.
Different mechanics, same underlying intuition: diverse models making different mistakes, combined, beat any single model.
💡 If you only remember one thing from this post: LEARN MANY MODELS, NOT JUST ONE. Ensembles reduce variance, handle complex patterns, and often perform better than even the best single model.
Next up — Post 7: Types of Machine Learning Systems.