
Table of Contents
Last update: June 2026. All opinions are my own.
ML Foundations · Post 7/10
ML systems get sorted along three axes. Knowing the labels makes it easier to compare any new algorithm you meet to the ones you already understand.
How much supervision do they get?
- Supervised — labelled examples. You know the answer for the training data; the algorithm learns to predict it. Classification, regression. The bulk of what most ML courses cover.
- Unsupervised — no labels. The algorithm finds structure on its own. Clustering, dimensionality reduction (PCA).
- Semi-supervised — a small amount of labelled data and a lot of unlabelled data. Useful when labelling is expensive — medical images, where each label costs a radiologist's time.
- Reinforcement learning — the algorithm interacts with an environment, gets rewards or punishments, and learns a policy. AlphaGo, robotics, recommendation systems. A genuinely different framework: there are no labelled examples, just a feedback signal that arrives slowly.
Do they learn incrementally?
- Batch learning — train once on the whole dataset, deploy. To incorporate new data, retrain from scratch. Most ML in practice is batch.
- Online learning — train continuously as new data arrives. Useful for systems that need to adapt fast (recommendation, fraud detection) or for datasets too large to fit in memory at once.
How do they generalize?
- Instance-based — store the training data and compare new examples to it directly. KNN is the canonical example: the model is the training set. Slow at inference time; no training time.
- Model-based — fit a model with parameters; throw away the training data after fitting. Linear regression, neural nets, almost everything else. Slow at training; fast at inference.
How predictions are made
Two contrasting styles:
- Lazy / instance-based. Store data, compare with new instance. KNN.
- Eager / model-based. Build a parametric function during training and use it to make predictions. Most of what you'll meet.
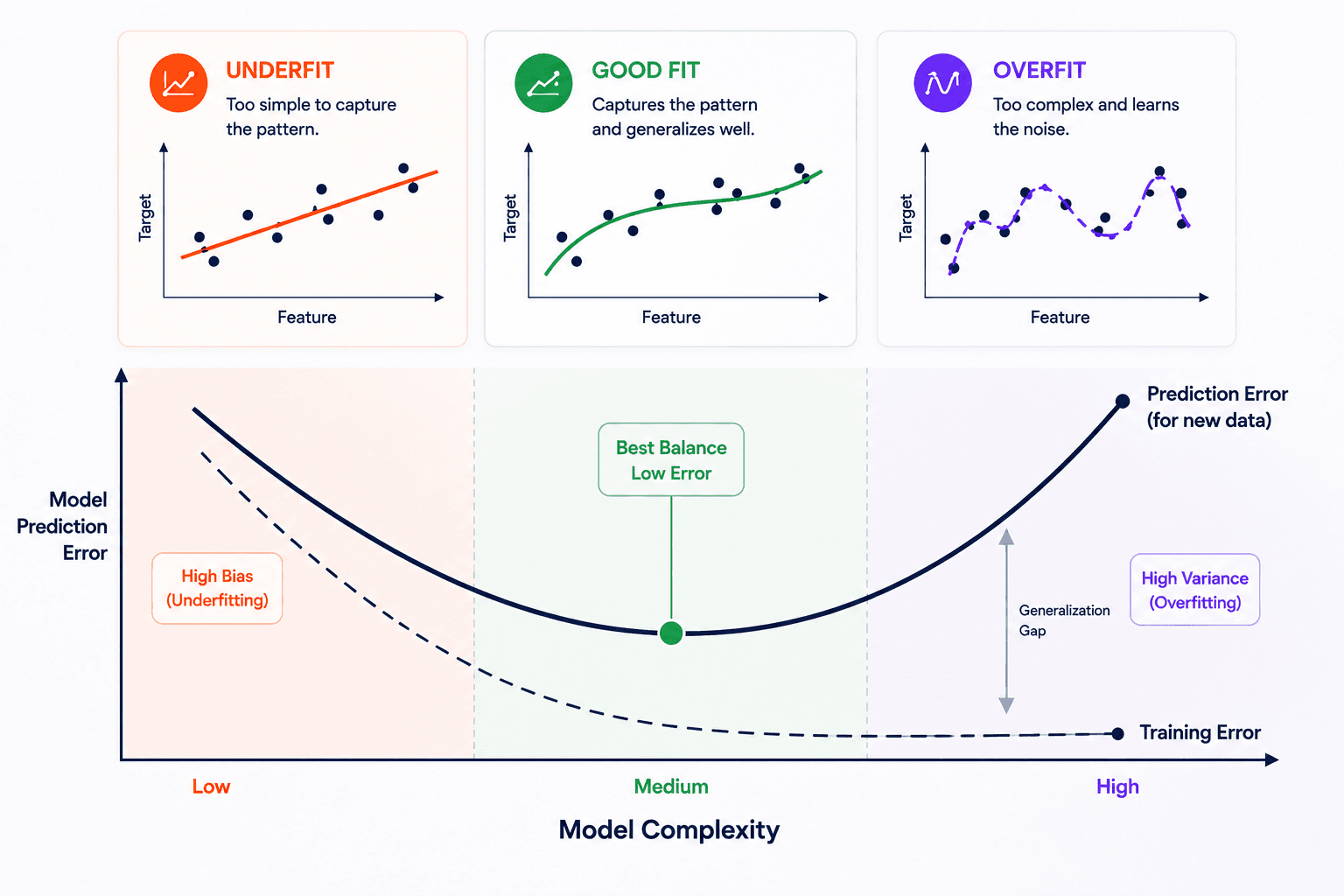
Almost every system in the foundations lives in the upper-left quadrant: supervised, batch, model-based. That's not because the others don't matter — it's because that quadrant is the cleanest place to learn the principles. The rest are variations on the theme.
Next up — Post 8: Main Challenges in Machine Learning.