
Table of Contents
Last update: June 2026. All opinions are my own.
A short companion to Part 6 — Text Classification: Classical and Part 7 — Text Classification: Deep Learning. Same machine — document in, class out — eight different jobs.
For each one: what the problem looks like, what technique usually wins in production, and the gotcha that bites you when you ship it.
Personalization
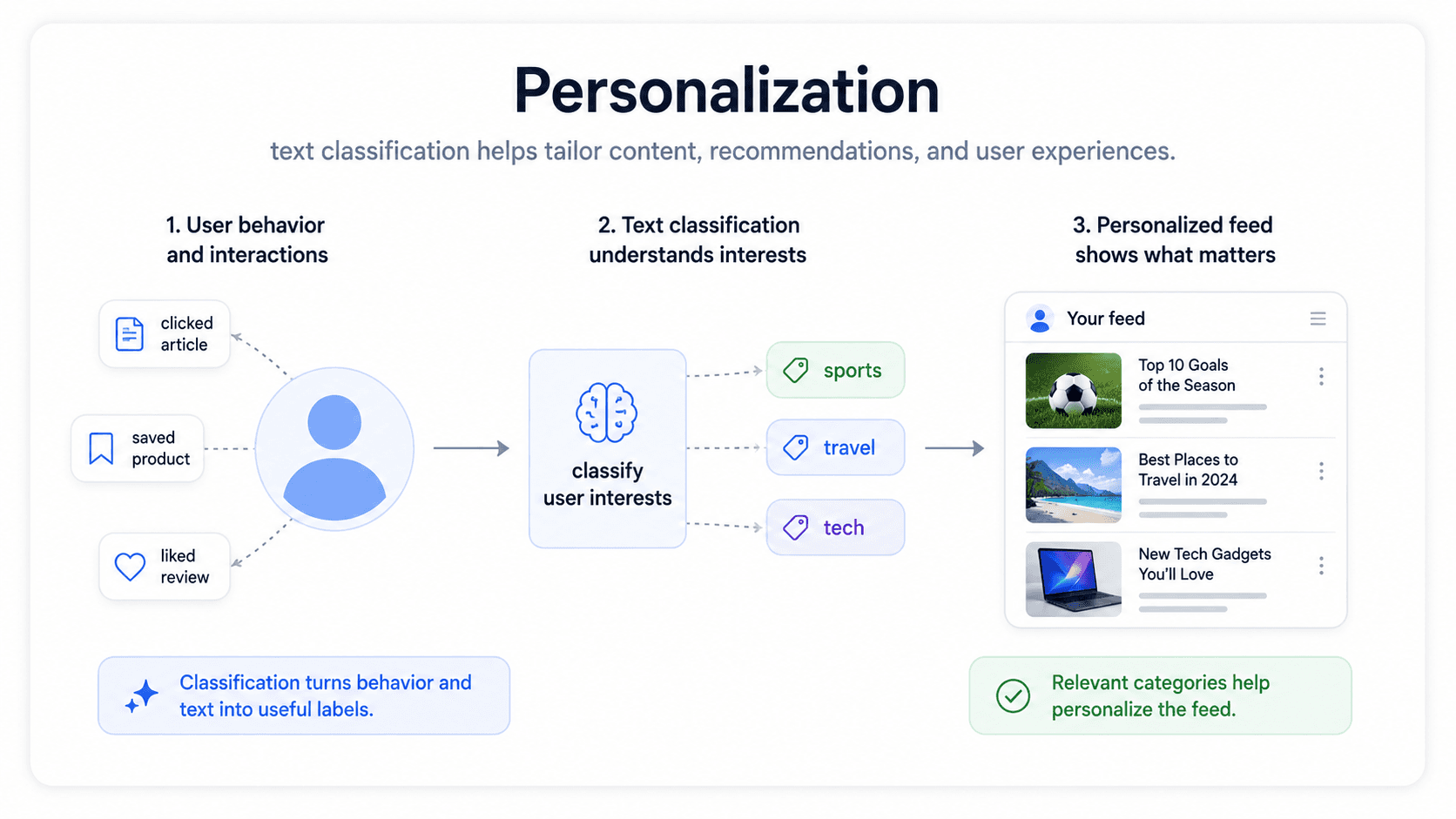
Most personalization is a text-classification problem in disguise. Tag every item in the catalogue (article, product, track, video) with its topics, then match users to items whose topics they like. The interesting part is not the recommender — it's the tagging pipeline that classifies a million items per day with no human in the loop.
The technique that fits: usually a fine-tuned transformer for tagging accuracy, with classical TF-IDF + LR as the always-on fallback when latency budgets are tight. The production headache: taxonomy drift. The set of topics you classify into keeps changing as the product evolves, and that means you keep re-labelling.
Authorship attribution
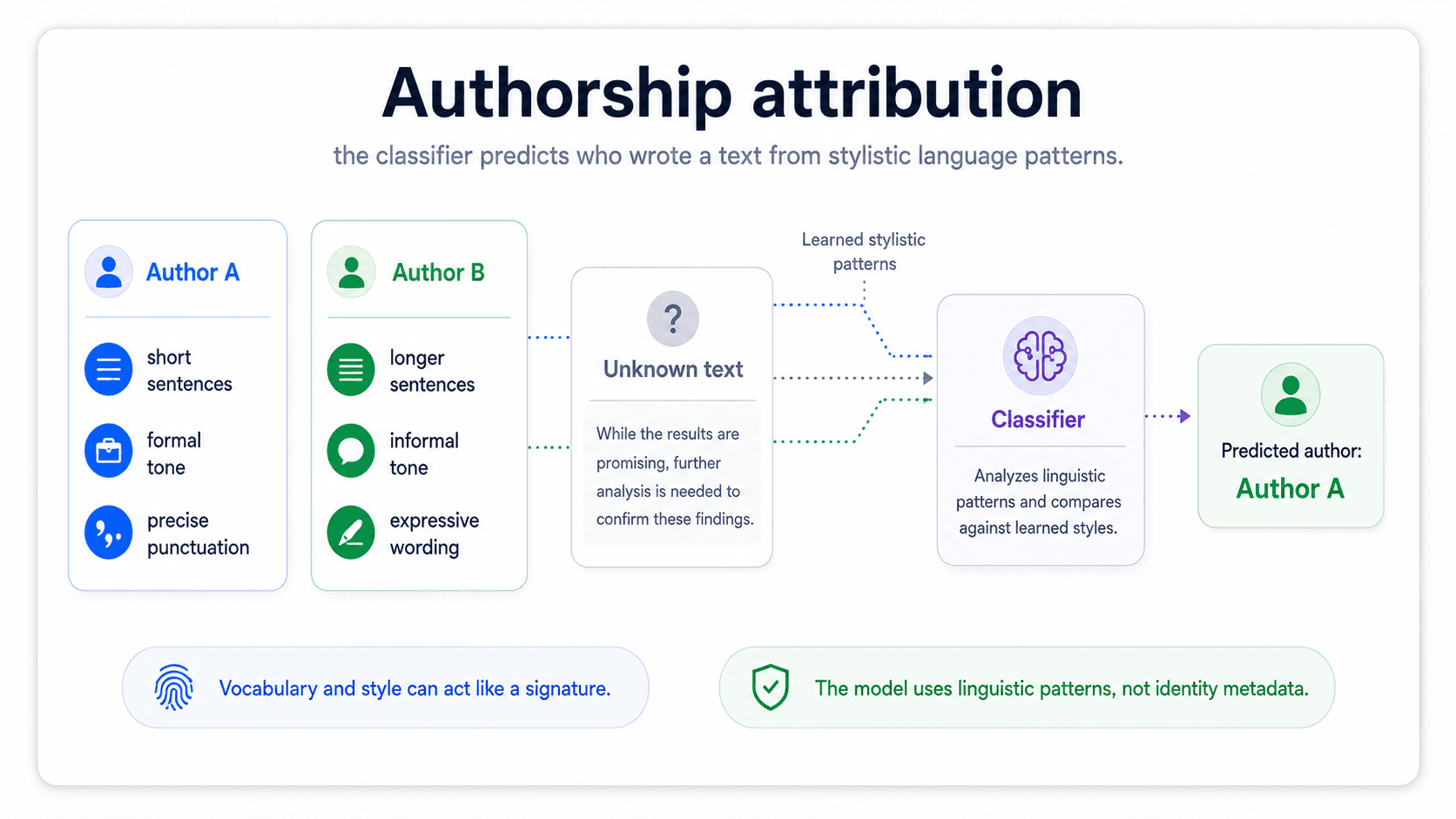
Given a passage, identify the author from a fixed list of candidates. Historically it was used on disputed works (the Federalist Papers, anonymous essays); modern versions are used to detect AI-generated text, identify ghostwriters, and verify identity in forensic settings.
The technique that fits: classical features (character n-grams, function-word frequencies, punctuation patterns) feeding a logistic regression or SVM are surprisingly hard to beat. Stylometry is a signal that lives at a level large pretrained models often blur over. The production headache: the gallery problem. Adding a new candidate author means re-training from scratch.
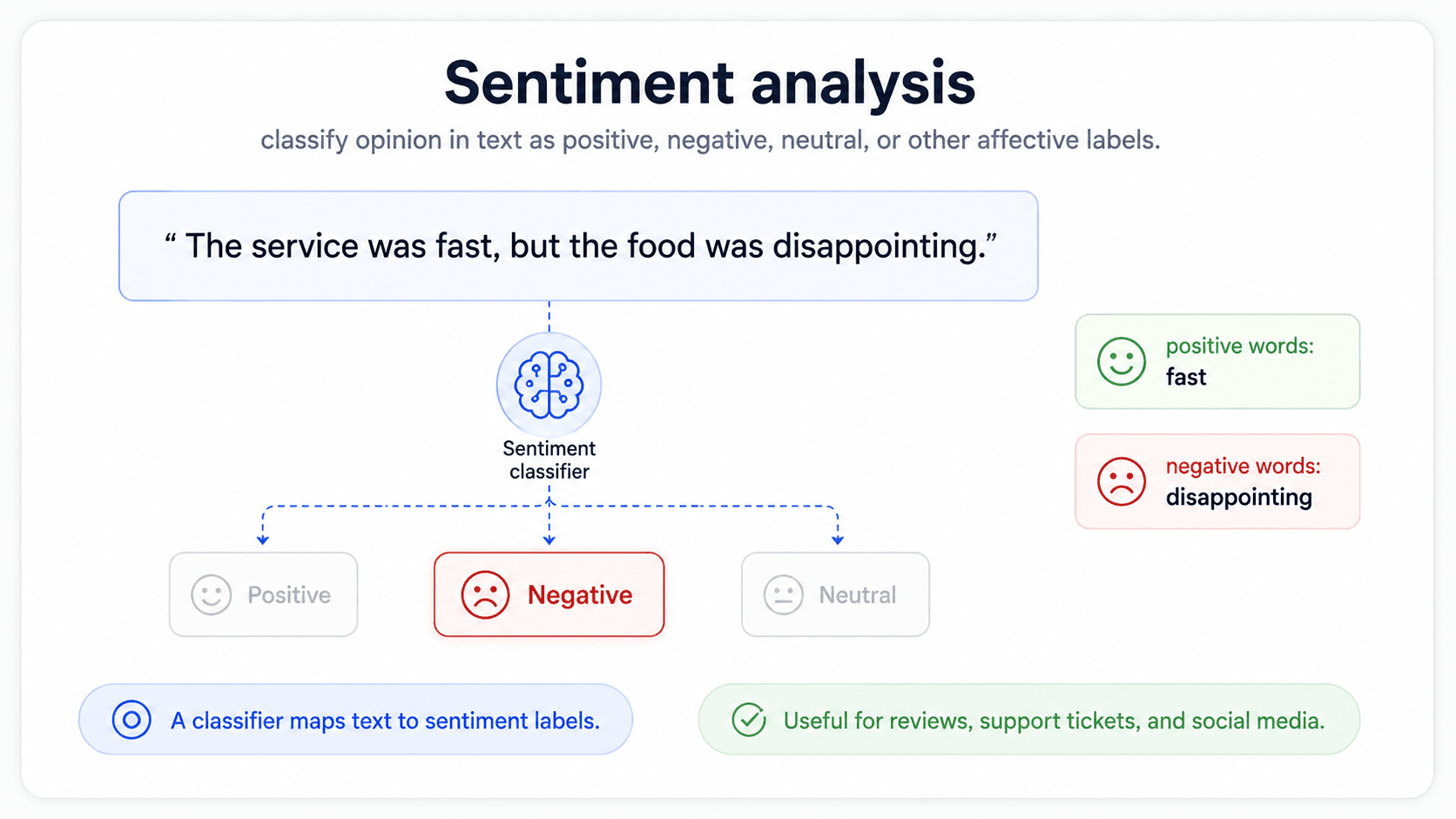
Sentiment analysis
Positive, negative, neutral — sometimes finer (5-star, multi-emotion). The canonical NLP classification task, and the one with the most public benchmarks. In production you see it on product reviews, support tickets, social media monitoring, and "voice of customer" dashboards.
The technique that fits: transformer fine-tuning (BERT, RoBERTa) is the modern default; a TF-IDF + LR baseline still gets you ~80% on most public datasets and tells you whether the labels are clean. The production headache: sarcasm and negation — the bag-of-words gives up here, and even good transformers are inconsistent.
Spam detection
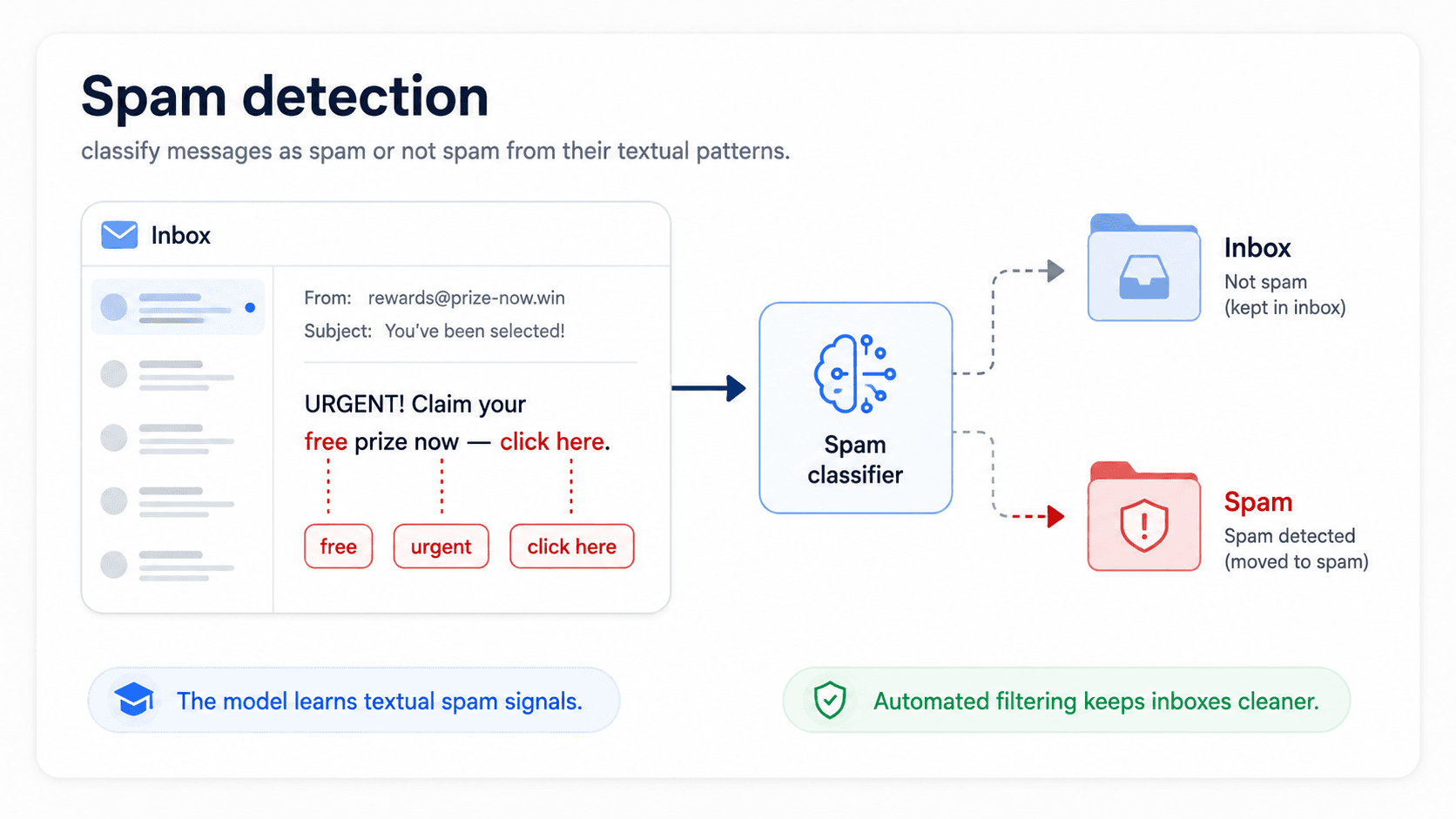
Binary. Spam or ham. The canonical introductory example for a reason: clean labels, large datasets, immediate stakes. Used in email, SMS, comments, reviews, and increasingly in messaging apps.
The technique that fits: Naïve Bayes still ships in production filters because it's fast, interpretable, and good enough; the heavy lifting today is feature engineering (URLs, sender reputation, header metadata) and adversarial robustness. The production headache: attackers evolve. Every classifier you ship has a half-life — your spam filter needs to retrain weekly to keep up with new tactics.
Age and gender inference from text
Predict a demographic attribute (age group, gender) from a writing sample. Researched extensively in academic settings; deployed cautiously where at all. The signal exists — lexical and syntactic patterns correlate with demographic groups — but the production case is narrow and the ethical case is uncomfortable.
The technique that fits: pretty much any text classifier works; the differentiator is feature engineering and the labelled corpus. The production headache: the ethics, not the technology. Most products that try this end up reinforcing stereotypes or violating user expectations, which is why you mostly see it in research or in carefully scoped editorial tools.
Language identification
Detect which language a piece of text is written in. Used everywhere — search routing, translation pipelines, content moderation, locale auto-selection. A solved problem on long text; an unsolved problem on short text and code-switching.
The technique that fits: character n-gram features feeding a logistic regression or even simpler model (think fastText). For long documents this is essentially a solved problem. The production headache: tweets, search queries, and chat messages are short and noisy, and people code-switch mid-sentence — that's the hard case where production systems still fail visibly.
Sarcasm detection

Decide whether a piece of text is meant sarcastically. Used in social media moderation, customer feedback analysis, and any sentiment system that wants to avoid being fooled by "oh, great, another meeting".
The technique that fits: transformer-based classifiers with context windows large enough to catch tone shifts; classical methods struggle badly here because sarcasm is precisely the case where surface lexicon contradicts intended meaning. The production headache: domain shift. A sarcasm classifier trained on Twitter does not transfer cleanly to product reviews.
Fake news detection
Classify whether a news article is misleading or fabricated. The most consequential application on this list, and the one where pure text classification falls shortest. Real systems combine NLP signals (writing style, framing) with knowledge-base lookups, fact-checking pipelines, and source reputation graphs.
The technique that fits: classification is only one component of a larger system — and the classifier alone gives a style signal, not a truth signal. The production headache: adversaries adapt faster than retraining cycles, and the cost of false positives is catastrophic for press freedom. This is where text classification becomes a political problem, not a technical one.
What this connects to
You now have the working catalogue. Eight problems, same shape — document in, class out — eight different techniques, eight different production headaches.
The methodology you'd reach for in each case is exactly the decision tree from Part 6: how much labelled data do you have, how adversarial is the environment, how much can you spend on inference. For the modern fine-tuning workflow that powers most of these in production today, see Part 7 — Text Classification: Deep Learning.
The pattern that keeps showing up: text classification stops being about which classifier the moment you take it out of the textbook. In production it's about feature engineering, label quality, taxonomy drift, adversarial pressure, and the social context you're deploying into.