
Table of Contents
- 1. Where we left off
- 2. Deep learning needs lots of annotated data — that is the catch
- 3. RNNs and CNNs: bigger models, but still trained from scratch
- 4. Language modelling as a new representation
- 5. Long-range dependencies are the bag-of-words killer
- 6. RNNs handle sequence — but only sequentially
- 7. Transformers and self-attention
- 8. Self-supervised learning: how the model learns without labels
- 9. Pretrained models: the representation, ready to download
- 10. Transfer learning: the workflow that ships
- 11. Removing the annotated dataset entirely
- 12. When to use which deep-learning approach
- 13. What this connects to
Last update: June 2026. All opinions are my own.
NLP from Scratch · Part 7/10
📋 In a hurry? The four-page cheat sheet for this post — deep representations, language modelling and pretraining, transfer learning and fine-tuning, and the zero-shot / prompt era — printable, downloadable, condensed for fast revision.
"Attention is all you need." — The 2017 title that made every other architecture obsolete for text.
Where we left off
In Part 6 you built a working text classifier with TF-IDF and logistic regression, and learned why it hits a ceiling: the bag-of-words representation cannot capture word order, polysemy, long-range dependencies, or context. The model isn't "speaking the language" — it is counting words.
This post is about the deep-learning side of the same problem. Same task — document in, class out — but a representation that can finally see meaning.
Deep learning needs lots of annotated data — that is the catch
Before the success stories, the honest part. Deep models are high-capacity. They have many more parameters than logistic regression, which is exactly what makes them powerful — but it is also what makes them hungry. A high-capacity model trained on a small labelled dataset will memorize, not generalize.
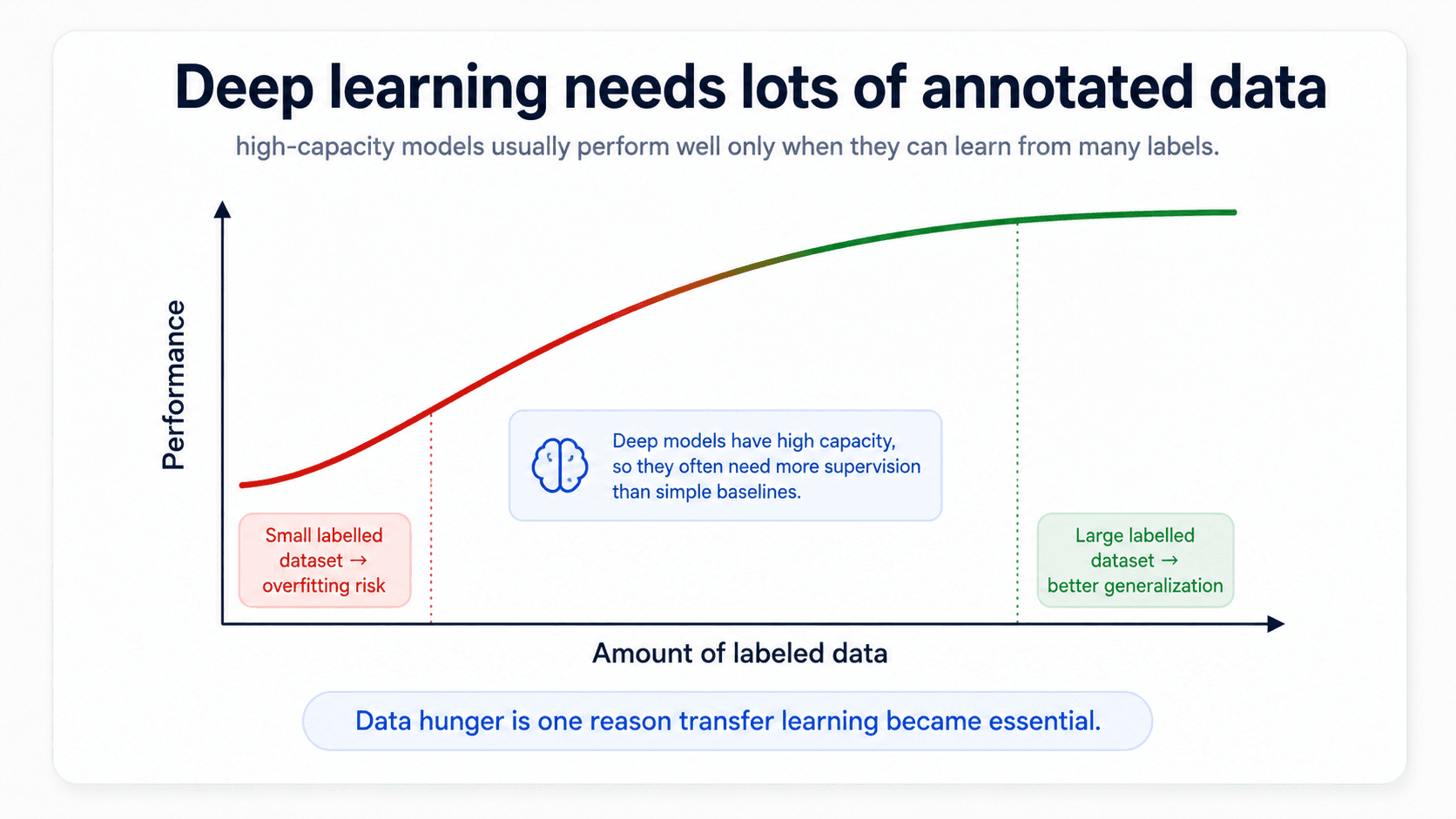
This is the question that motivates the whole rest of this post: how do we use big models without needing huge labelled datasets for every task? The answer turns out to be transfer learning, but to understand transfer learning we first need to understand what a language model is.
RNNs and CNNs: bigger models, but still trained from scratch
The first wave of deep learning for text was straightforward — replace the linear classifier with a deeper neural network. Two architectures got most of the attention:
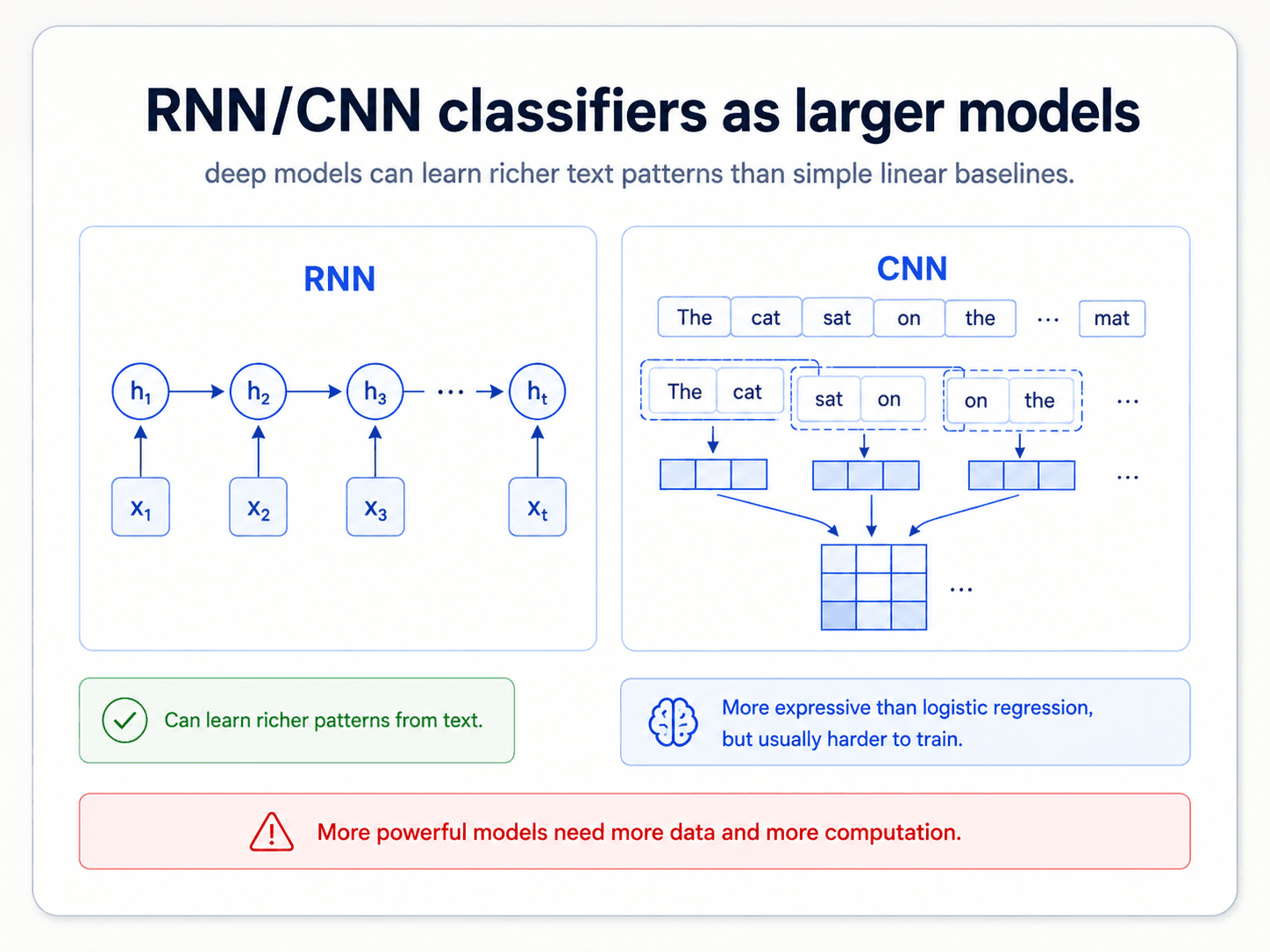
RNNs (recurrent neural networks) read the sequence one word at a time, updating an internal hidden state as they go. The hidden state carries information forward — so by the time the network has read the whole document, the state has (in principle) encoded everything that mattered.
CNNs (convolutional neural networks) slide small filters across the text, learning local patterns (n-gram-like) and then composing them into higher-level features.
The practical verdict from the notes is uncomfortable:
❌ Do not use CNNs for text classification. They had huge success on images and people tried to copy that to text. They can capture some textual structure, but they do not capture sequential information. RNNs (and later transformers) handle sequences properly; CNNs do not.
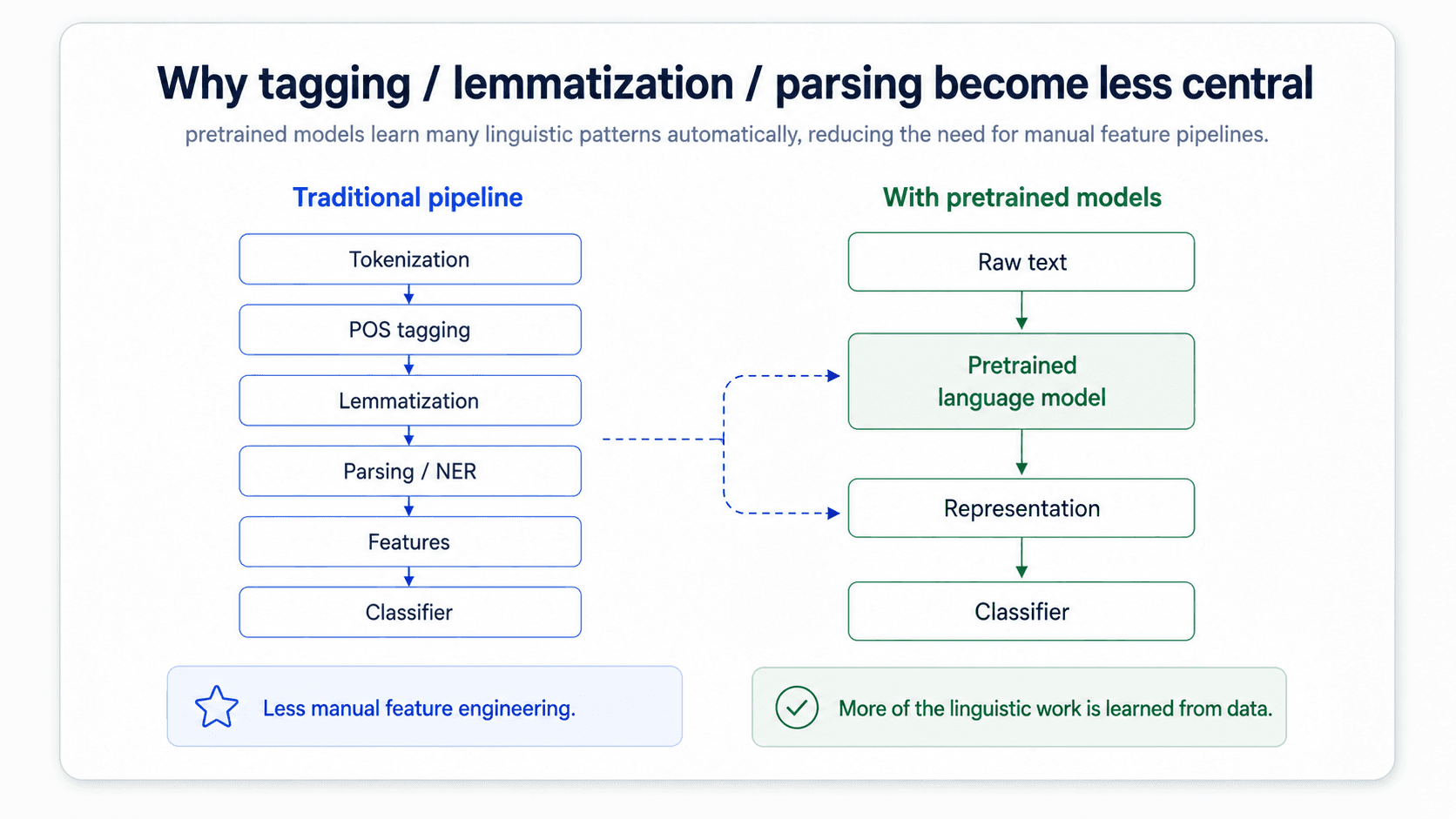
So RNNs win this round. But there is still the bigger problem — these networks are trained from scratch on the labelled dataset for each task. And as we just established, labelled data is the bottleneck.
The breakthrough was not a better architecture for the classifier. It was a better representation to feed it.
Language modelling as a new representation
Here is the move that changed everything. Instead of training a classifier directly on the bag-of-words, you first train a separate model to do something that does not need labels at all: predict the next word in a sentence. Then you use the representation that model learned as the input to your classifier.
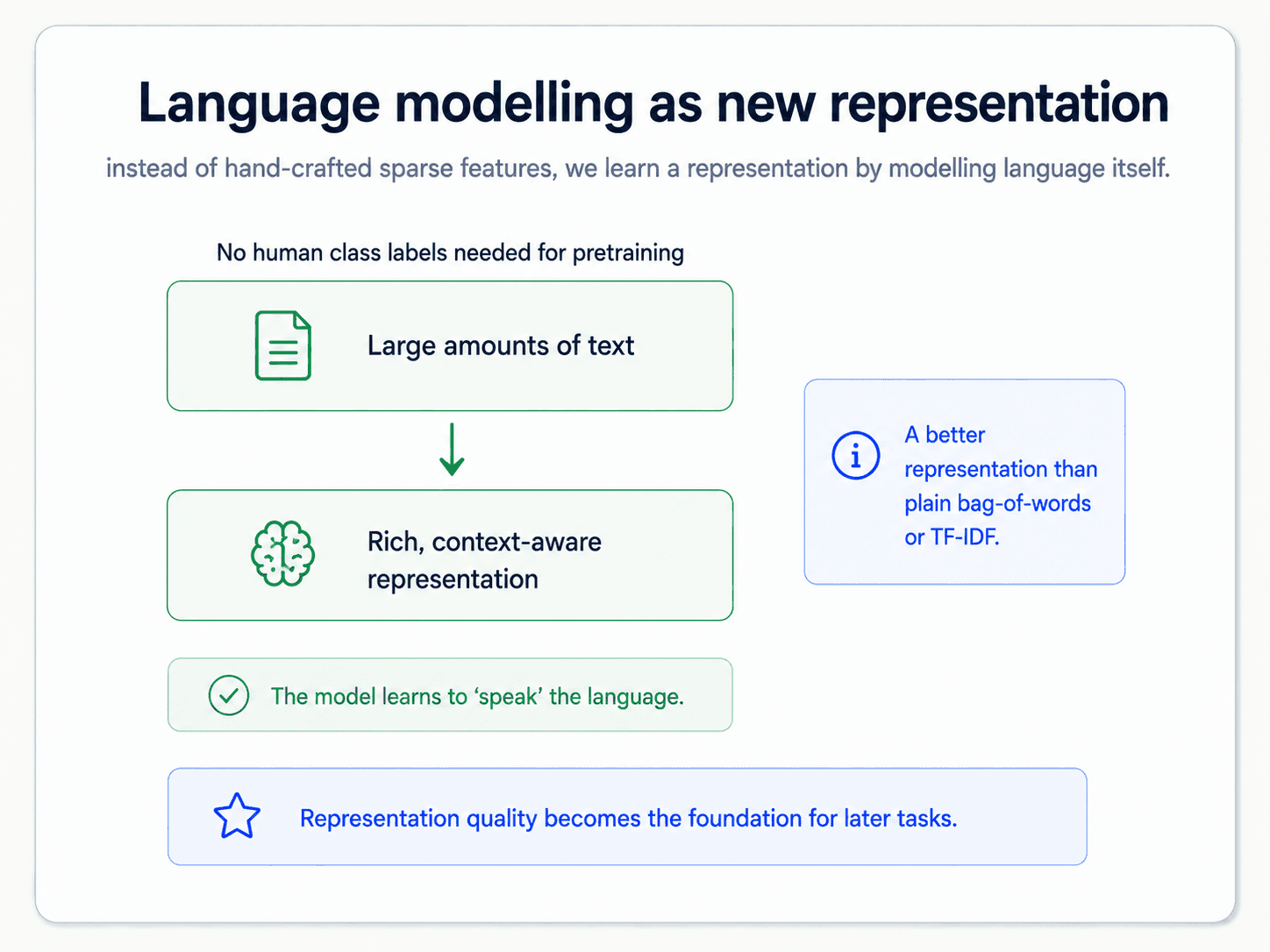
Why predicting the next word is such a powerful task — and why this is the move that lets you escape the labelled-data ceiling.
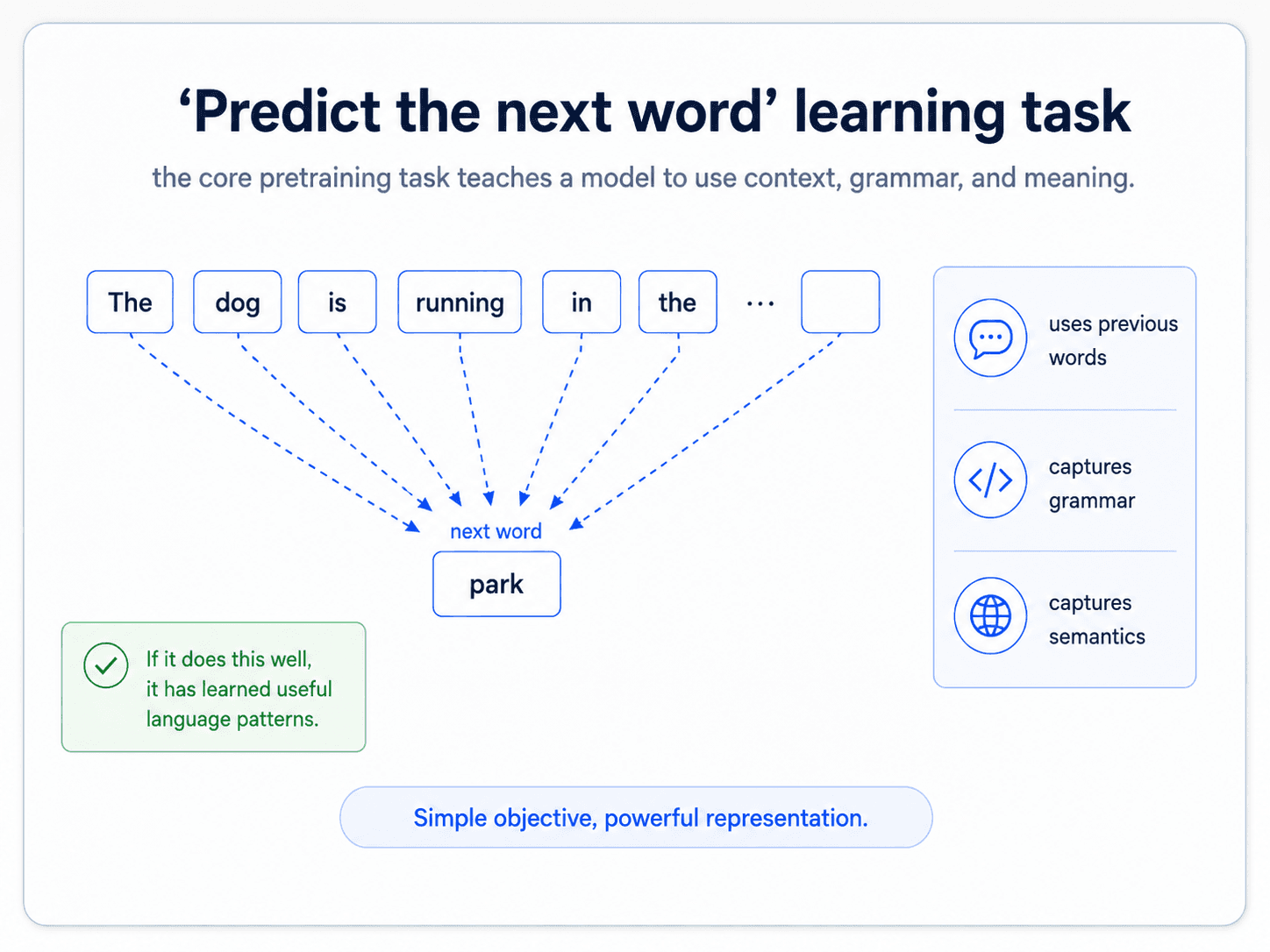
Looks trivially simple. It is not. To predict the next word well, the model has to understand:
- The grammatical structure of what came before
- The meaning of the words used
- The world knowledge those words imply
That is a lot to learn from a one-word objective. And it gets at the heart of why language modelling works:
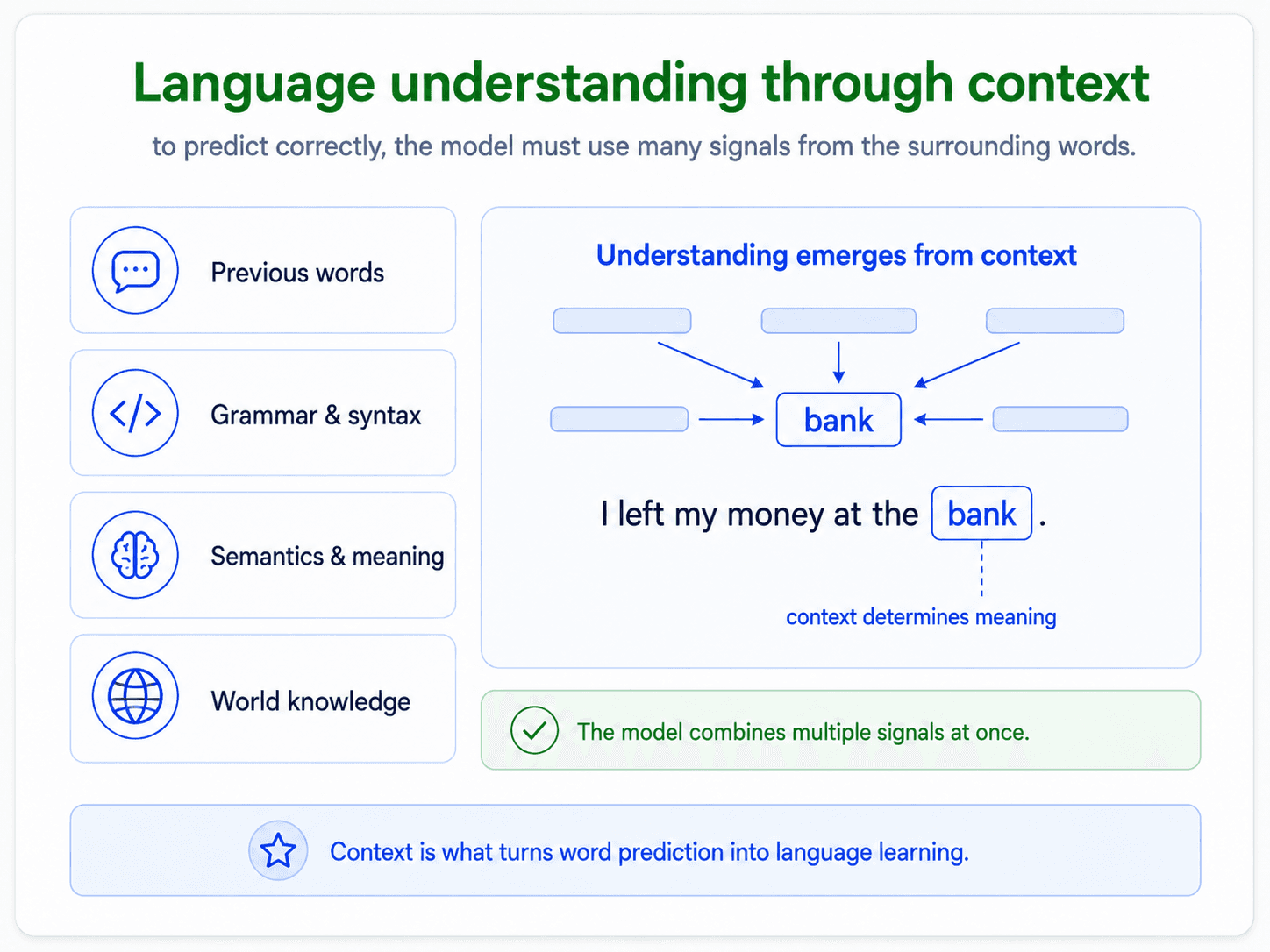
The reason this is such a big deal: it does not need any labels. A language model trains on raw text — Wikipedia, books, the web — and the "supervision signal" is just the next word in the sequence. No human annotation needed. That is the move that breaks the labelled-data ceiling.
Long-range dependencies are the bag-of-words killer
Before the deep-learning architectures, the classical answer to "model word order" was n-gram language models (covered in Part 5). They look at the previous N-1 words to predict the next one. But N is small in practice (2, 3, maybe 5), and that means n-grams can only see a short window. They miss long-range dependencies — which are everywhere in real language.
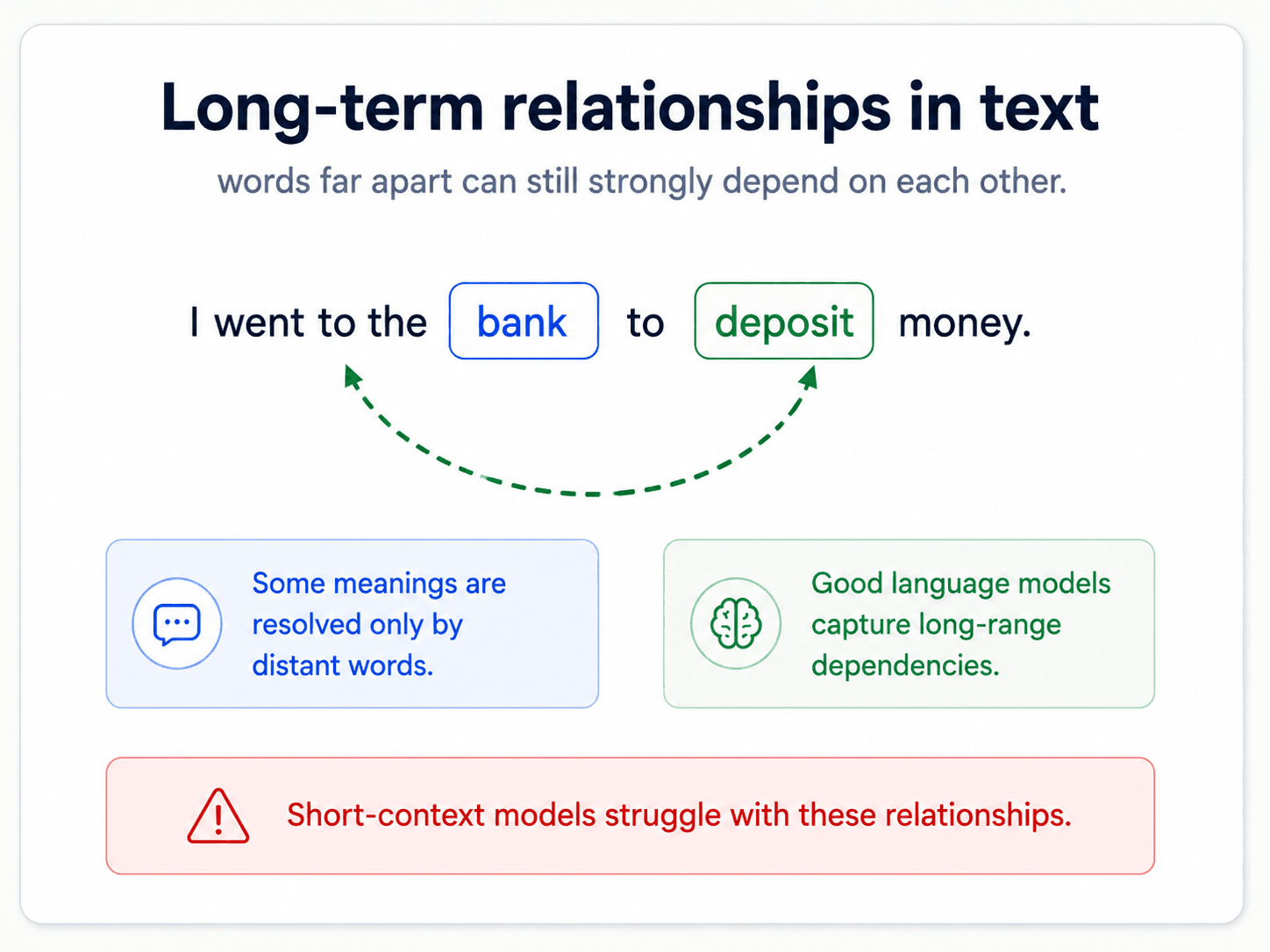
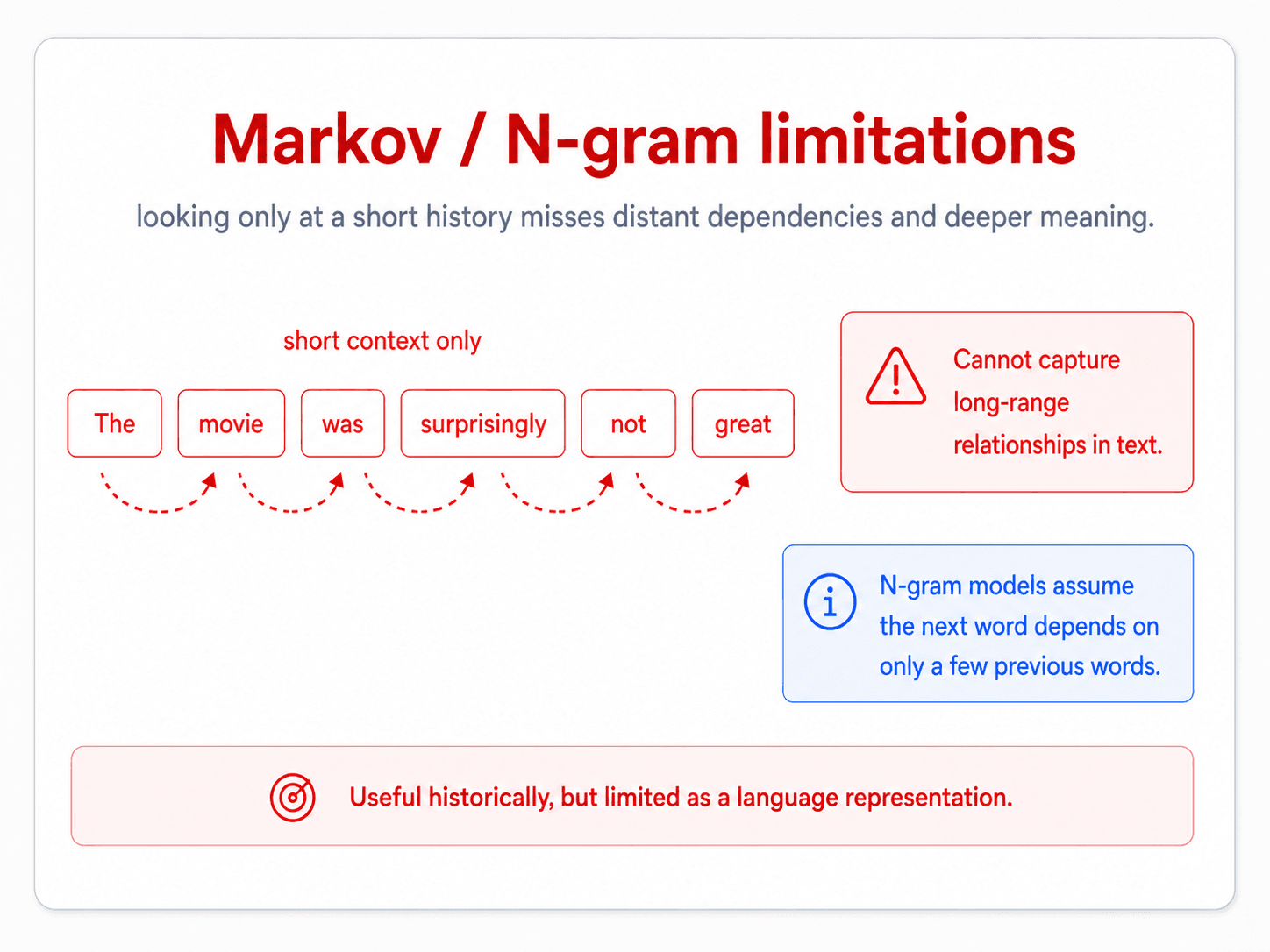
So the question is: which deep-learning architecture handles long-range dependencies?
RNNs handle sequence — but only sequentially
RNNs were the first answer. They read the sequence one word at a time, updating a hidden state.
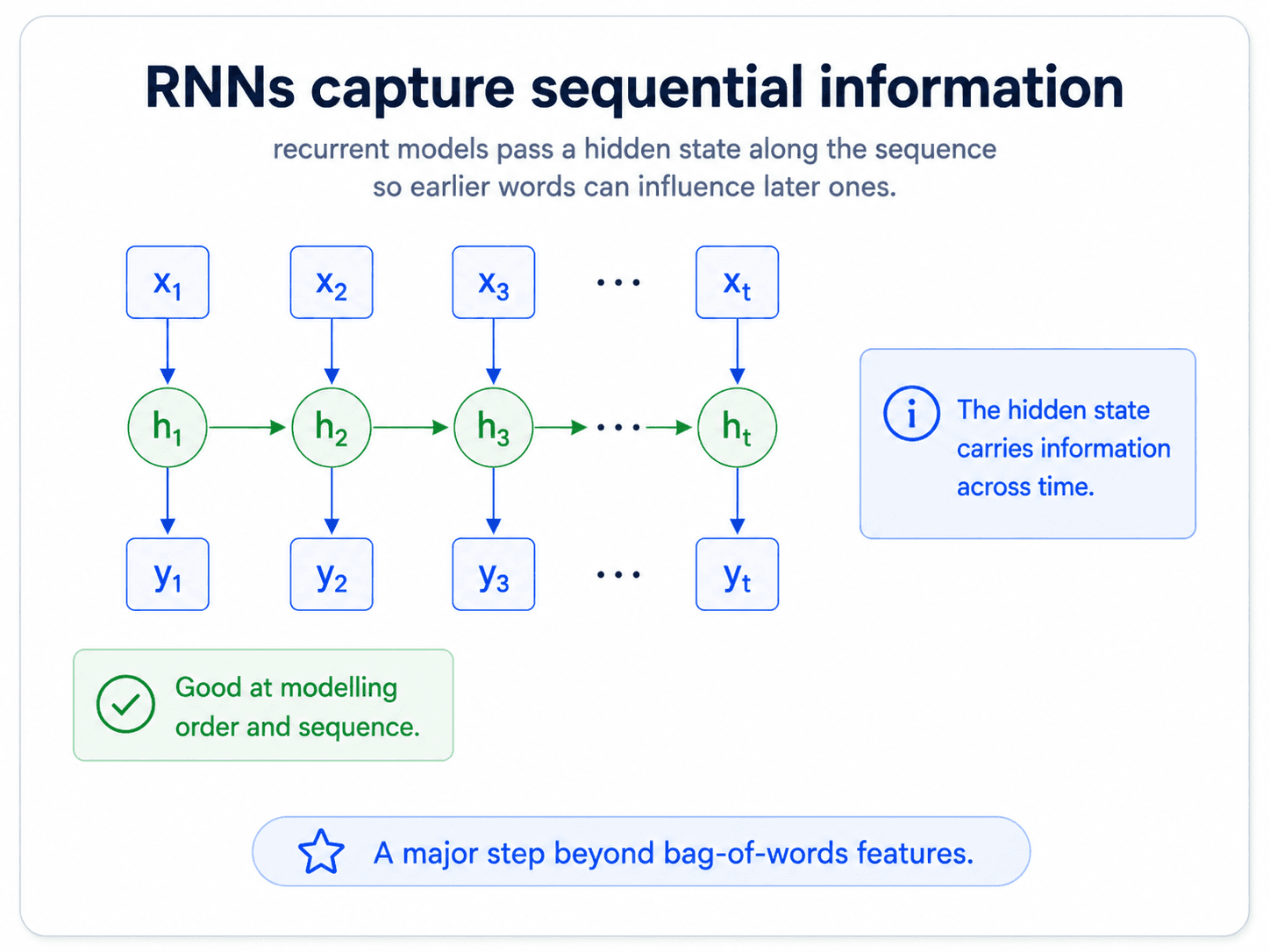
A bidirectional RNN runs the sequence in both directions and concatenates the hidden states, so each position has access to information from both its past and its future in the sentence. For classification you usually take the final hidden state (which has seen everything) and feed it into a logistic regression — and the notes are explicit: the prediction layer is what you usually throw away. The hidden state is the representation you actually wanted.
So RNNs solve the sequence problem. But they solve it sequentially: to relate word 1 and word 10, you have to flow information through every single word in between, even if those middle words are irrelevant. For long sentences, signal degrades over distance. And training is slow because the recurrence cannot be parallelized.
This is where transformers come in.
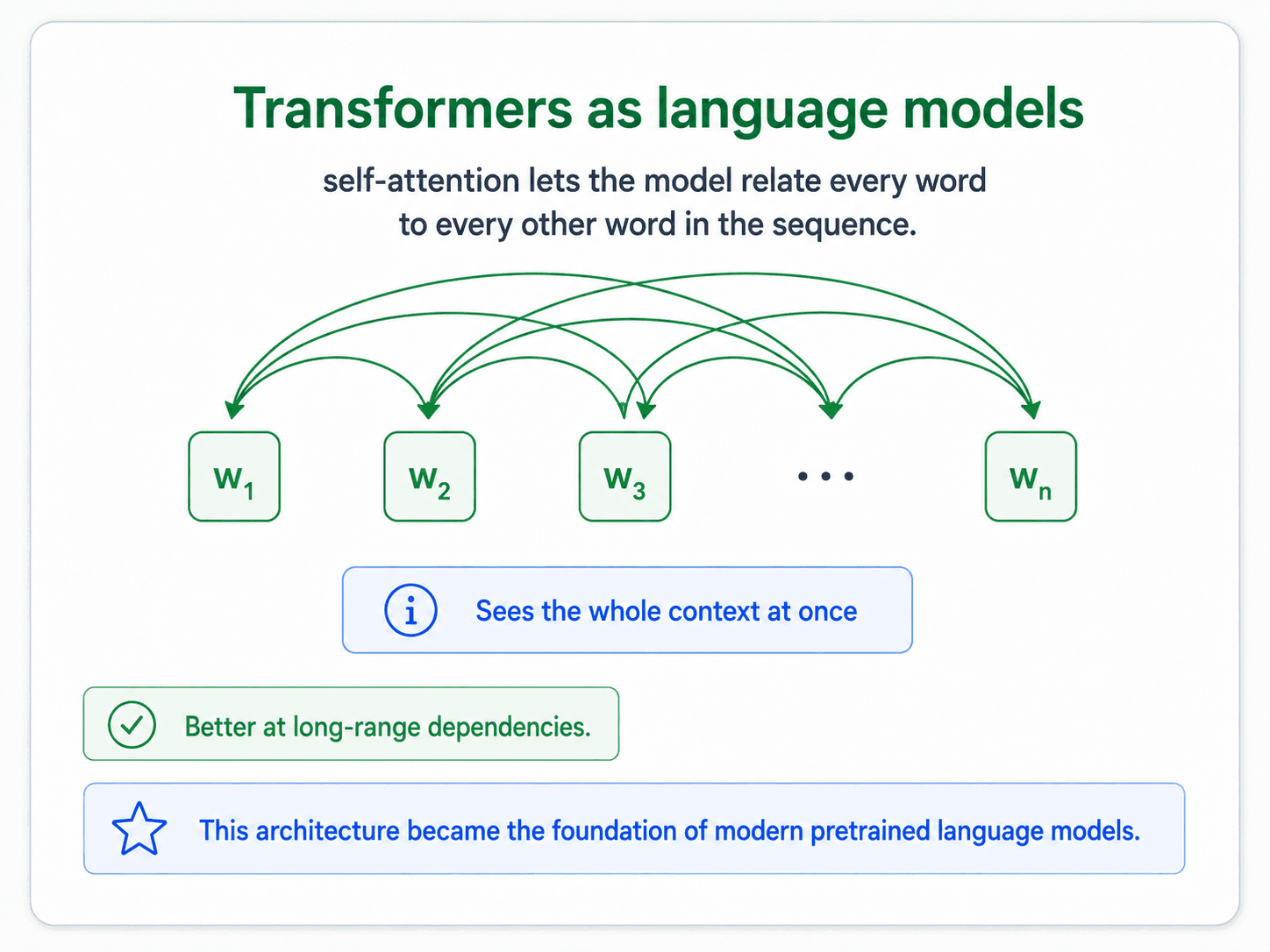
Transformers and self-attention
Transformers replace the recurrent chain with a single mechanism — self-attention — that lets every word in the sequence look directly at every other word.
The notes' framing of the RNN-vs-transformer difference is the cleanest version I have seen:
- RNN: to model the relation between word 1 and word 10, the network has to pass information through all the words in between — and those words might be irrelevant.
- Transformer: self-attention is "the sentence attending to itself". Each word can attend directly to any other word. Relationships are learned in parallel, not sequentially.
The trick: this needs a lot of data. Self-attention is powerful, but it has nothing built in that says "words near each other are related" the way an RNN does. The transformer learns that purely from data. Hence the explosion of "billions of parameters trained on terabytes of text".
The practical verdict from the notes is short: transformers are the preferred architecture. That has been true since 2018 and is still true.
Self-supervised learning: how the model learns without labels
We have been saying "predict the next word" as if it were trivial. Now let's put a name on what this actually is.
![A card titled 'Self-supervised learning'. Three boxes left to right: 'Raw text' (document icon) → 'Create own targets' (with a small dashed-box masking diagram) → 'Learn patterns' (with a neural-net icon). Below: two examples — 'predict next word' (the cat sat on the [mat]) and 'fill missing word' (the cat sat on the [____] mat). Right green callout: 'No manual labels are needed to learn useful representations.' Bottom blue note: 'The supervision signal comes from the text itself.' Bottom green check: 'This is what made large-scale pretraining possible.'](/_next/image?url=%2Fimages%2Fblog%2Fnlp-from-scratch%2Ftext-classification%2Fself-supervised-learning.png&w=3840&q=75)
The technical term is self-supervised learning. It looks like supervised learning (predict a label) but the labels are generated automatically from the text itself:
- Predict next word. GPT-style autoregressive language modelling. The label is just the next token.
- Fill missing word. BERT-style masked language modelling. Mask a random word and ask the model to fill it in from context.
This is what unlocks the move that breaks the labelled-data ceiling: we can now train enormous models on the whole internet of raw text, with no annotation. The cost is compute, not annotators.
Pretrained models: the representation, ready to download
Once you train a language model on enormous data, what you actually want is the representation it learned — the encoder. You can download it.
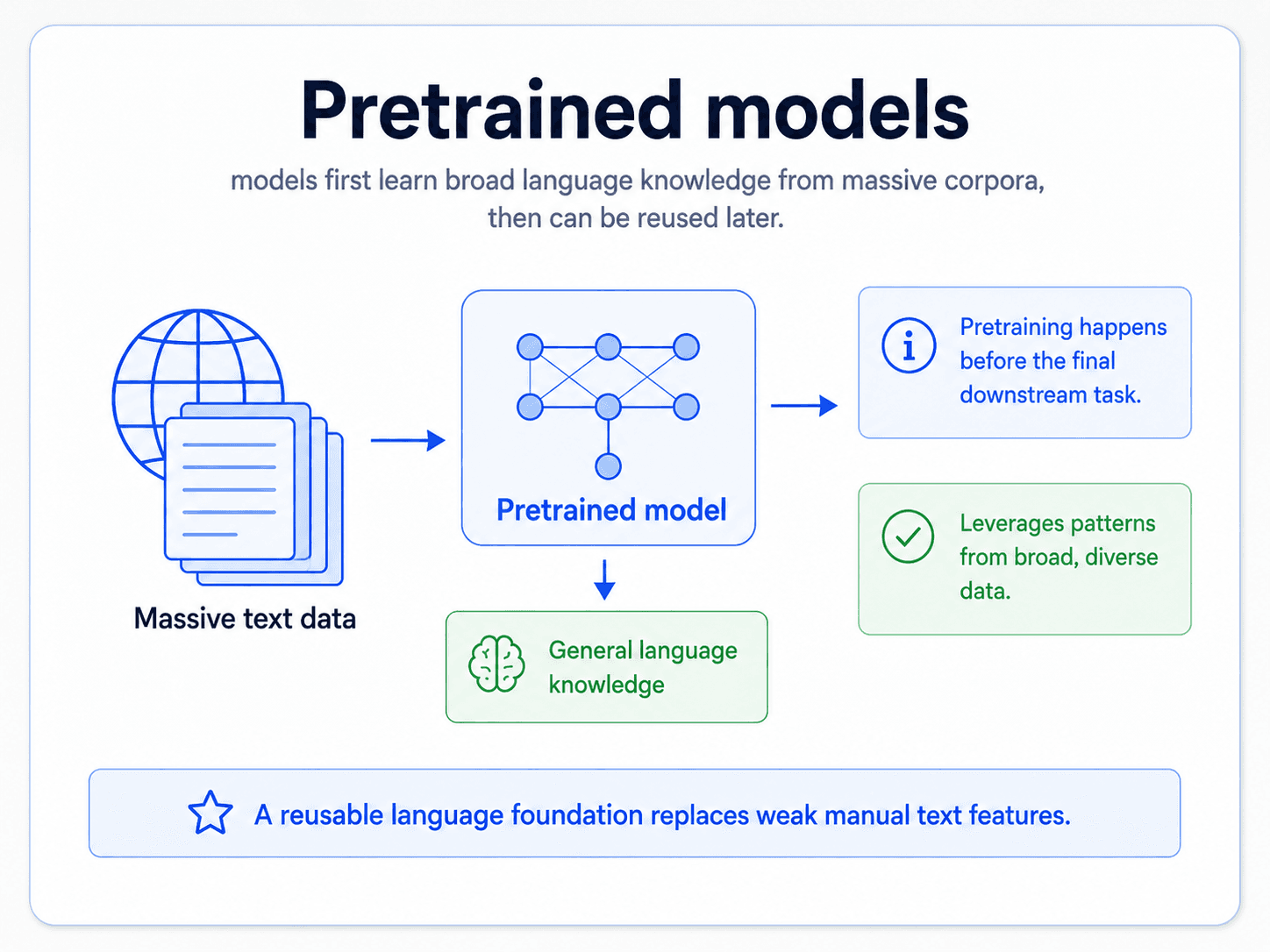
The familiar names — BERT, GPT, RoBERTa, LLaMA — are all this pattern. Each is a transformer pretrained on huge amounts of text. The clever bit is that you do not need to train one yourself. You download the weights from Hugging Face, attach a small classification head (basically a logistic regression) on top, and fine-tune on your tiny labelled dataset.
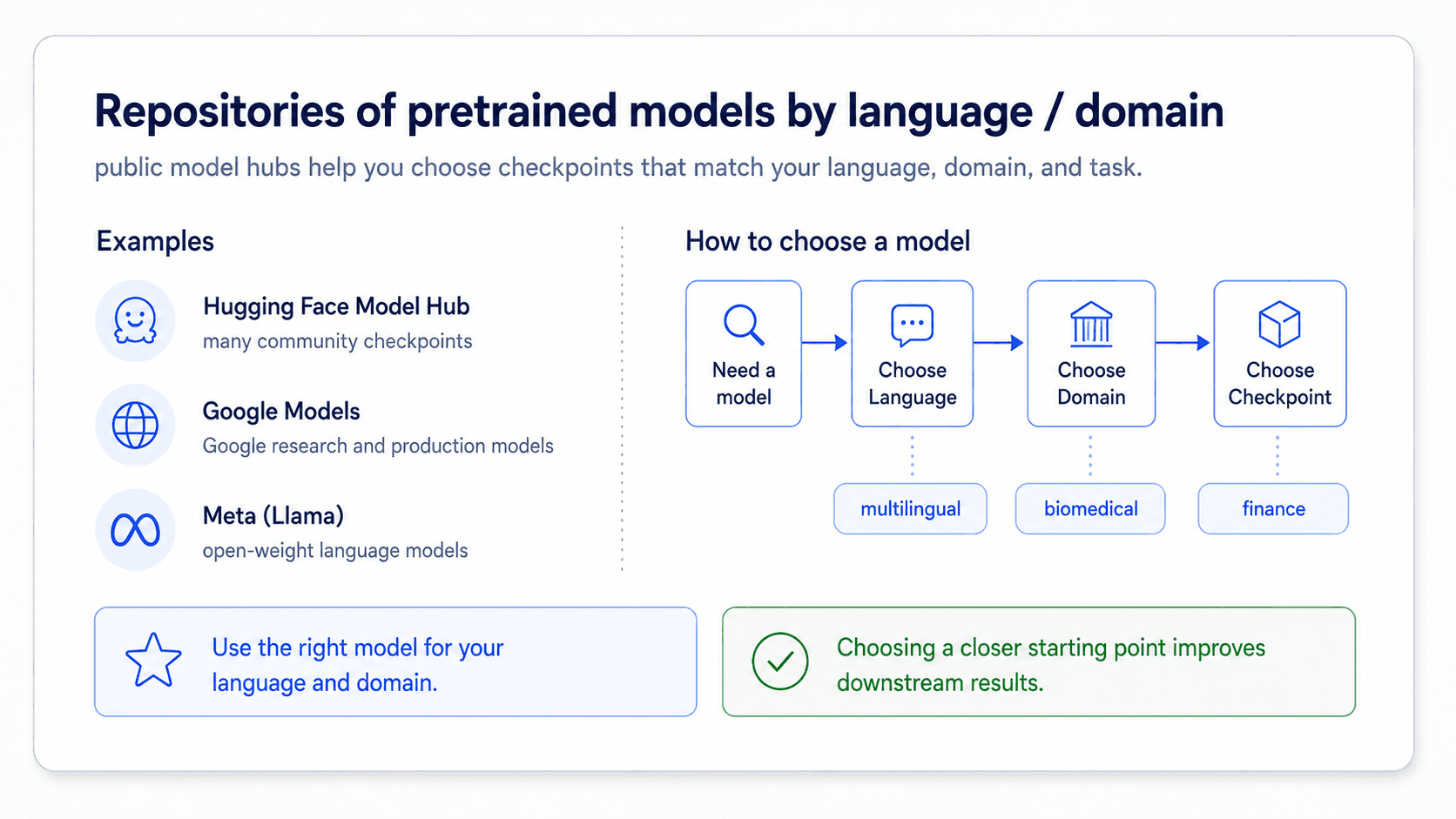
That is the move that ties everything together. It is called transfer learning, and it is the workflow you'll actually use in practice.
Transfer learning: the workflow that ships
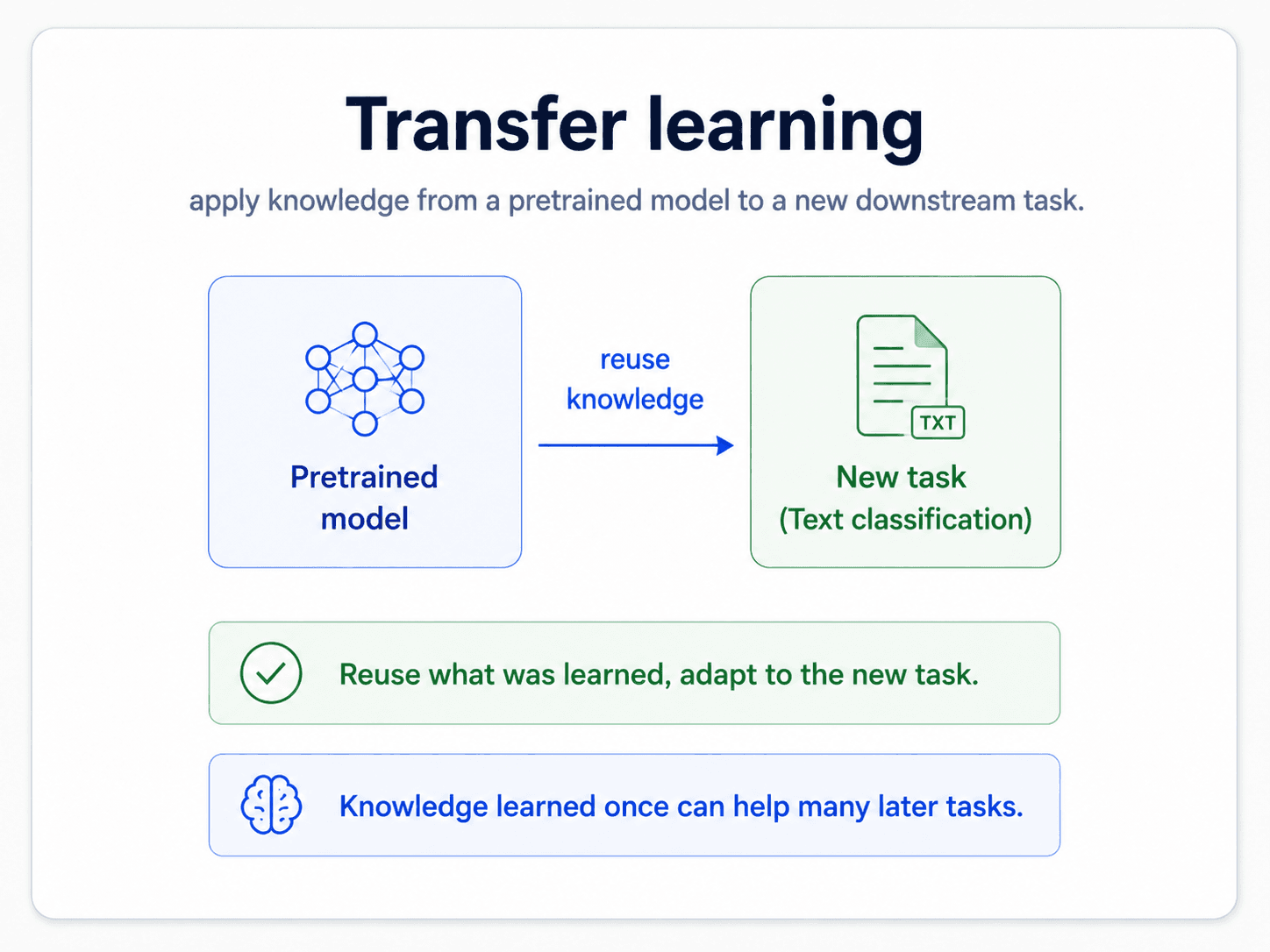
The setup has a name — fine-tuning — and the whole point is that you take a model that already speaks the language and gently update it for your specific task.
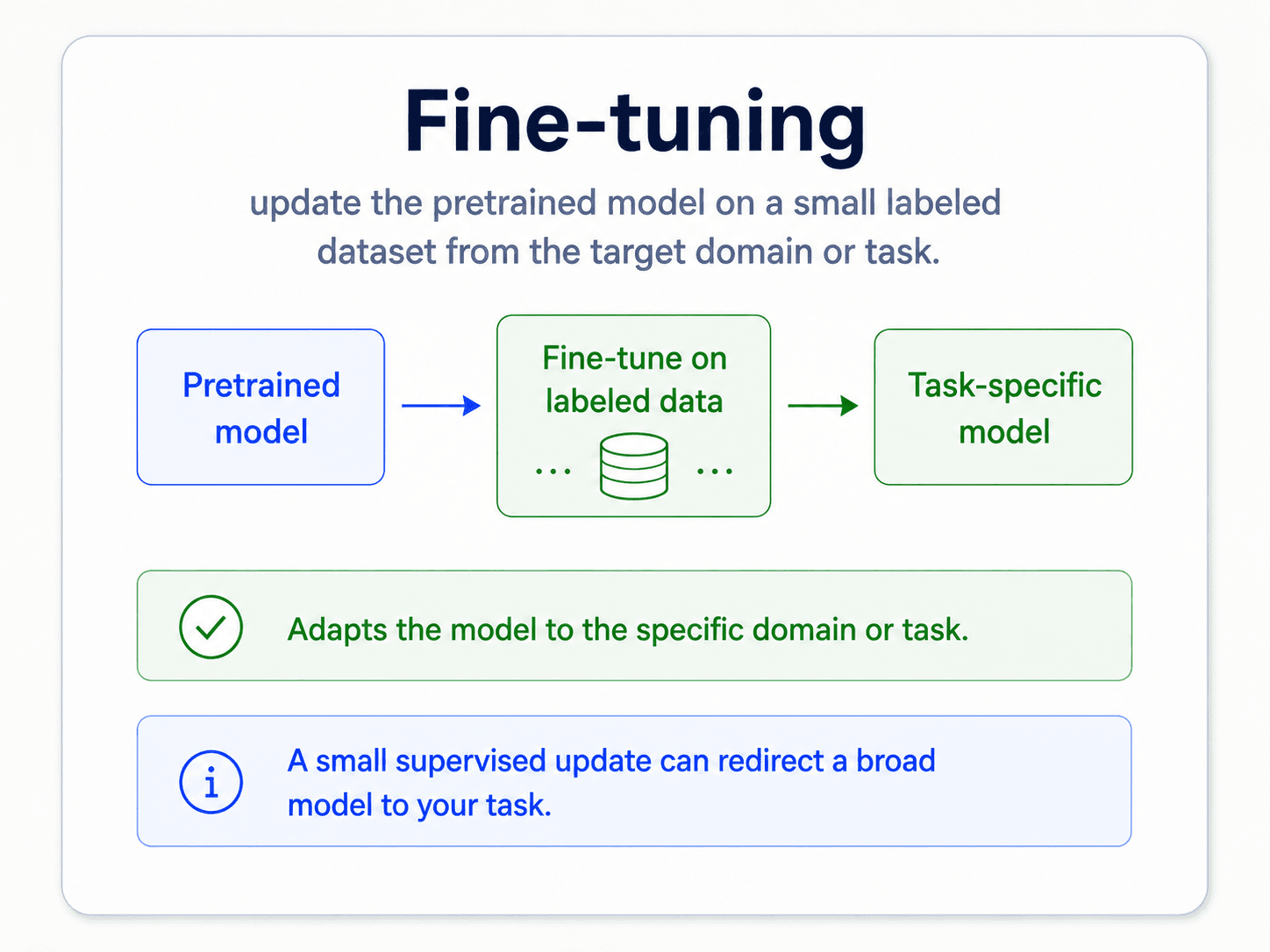
Three steps. The fast.ai sentiment-on-IMDb example is the canonical version of this chain:
- Pretrain a language model on huge unlabelled text. Someone has already done this. Download the weights. (In the IMDb example: Wikitext-103 — a corpus of cleaned English Wikipedia articles.)
- (Optionally) Fine-tune the language model on your domain. Take that same pretrained LM and continue language modelling on text from your domain — not on the classification labels yet. This teaches it the vocabulary and style of your data. (In the IMDb example: continue training the LM on raw IMDb reviews so it learns "moviespeak".)
- Fine-tune for your task. Attach a classification head — basically a logistic regression — on top of the domain-adapted LM. Train on your small labelled dataset. (In the IMDb example: now train the classifier head on the labelled positive/negative IMDb reviews.)
That step-2 detour is domain adaptation — you don't change the architecture, you just keep doing language modelling on text from your world. The model learns your domain's vocabulary, idioms, style. After that, the labelled fine-tune in step 3 is much smaller and much cheaper.
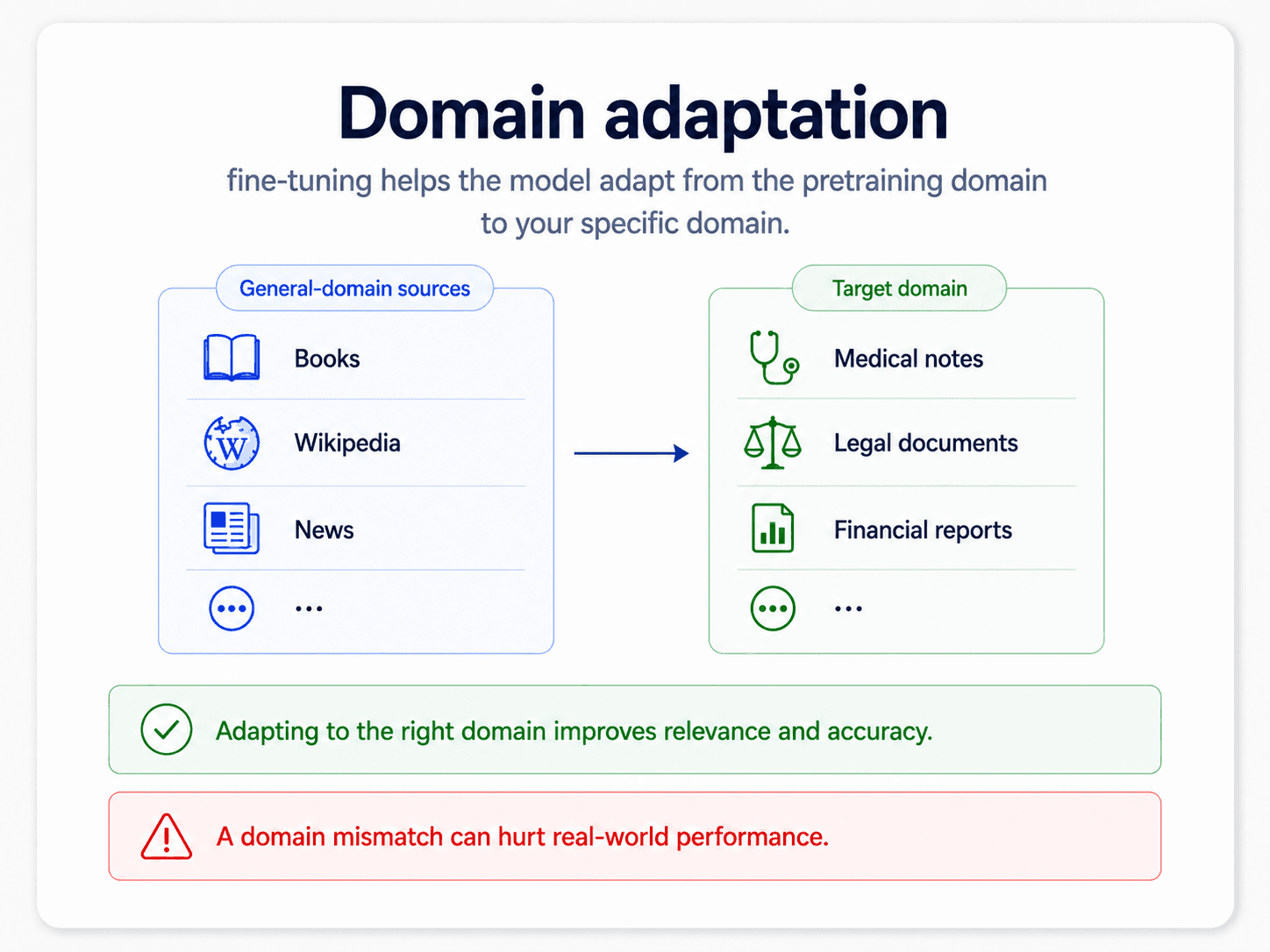
And step 3 is where the magic looks impossibly cheap — because by then the model has already done almost all of the heavy lifting.
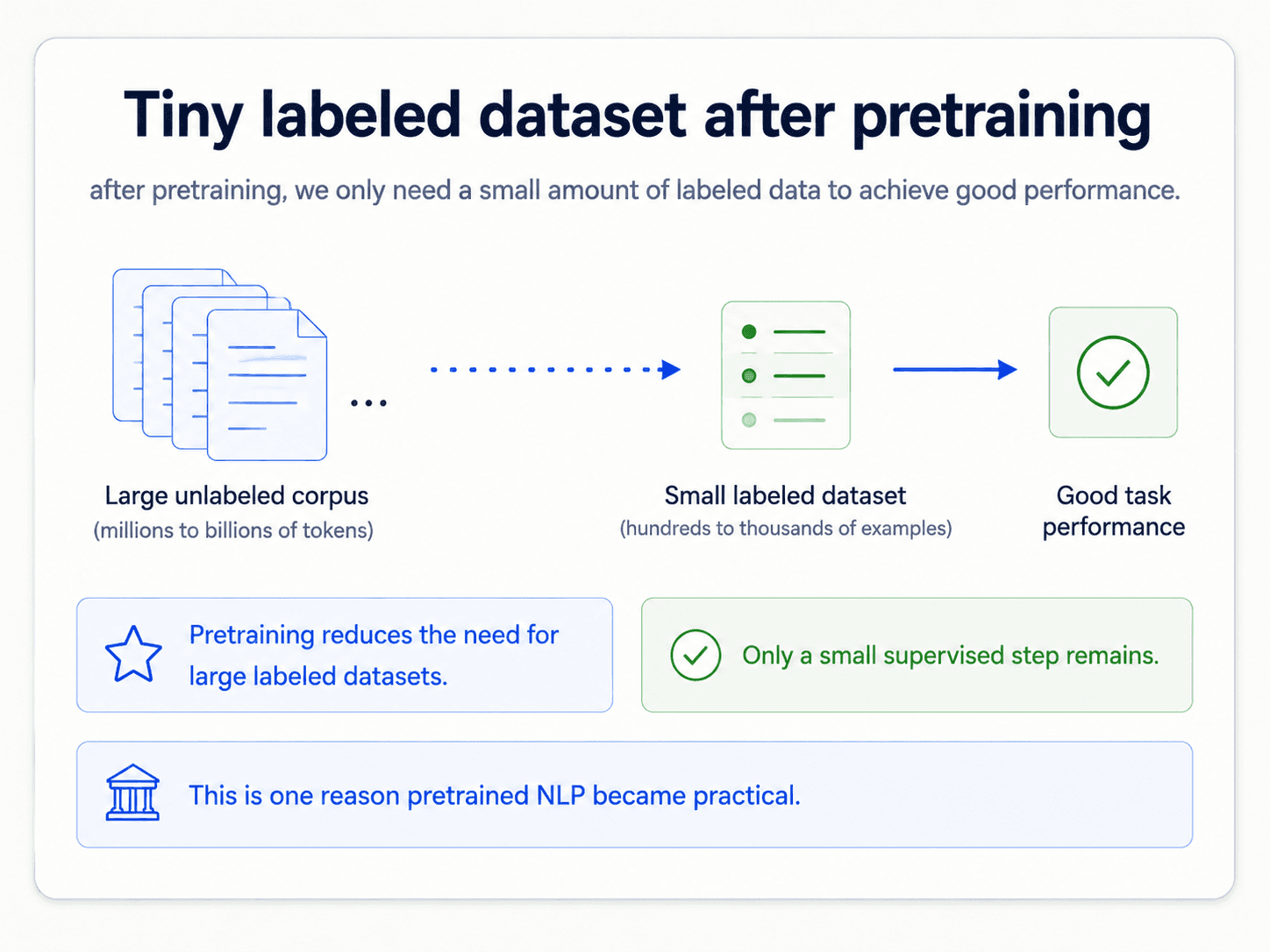
The whole point: by step 3 you have a model that already understands language, already understands your domain, and only needs to learn the specifics of your task. That last step typically needs orders of magnitude less labelled data than training a deep model from scratch.
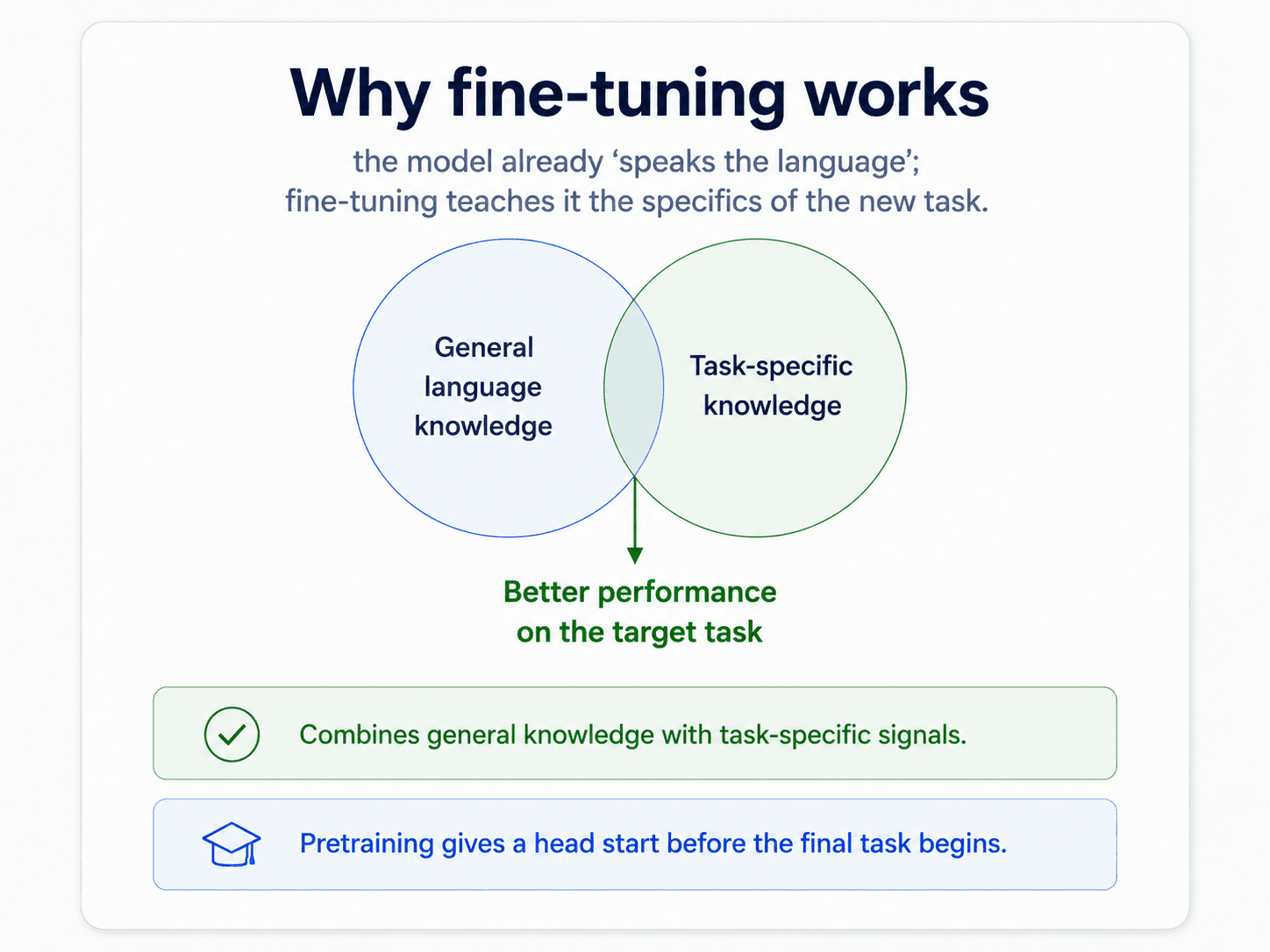
But step 3 is also where things break, and the notes are full of practitioner warnings. Let's walk them.
Catastrophic forgetting
This is the headline danger. If you fine-tune the language model on your domain too aggressively — too many epochs, too high a learning rate, training too many layers — the model forgets its general language knowledge. It overfits to your domain so hard that it loses what made it useful in the first place.
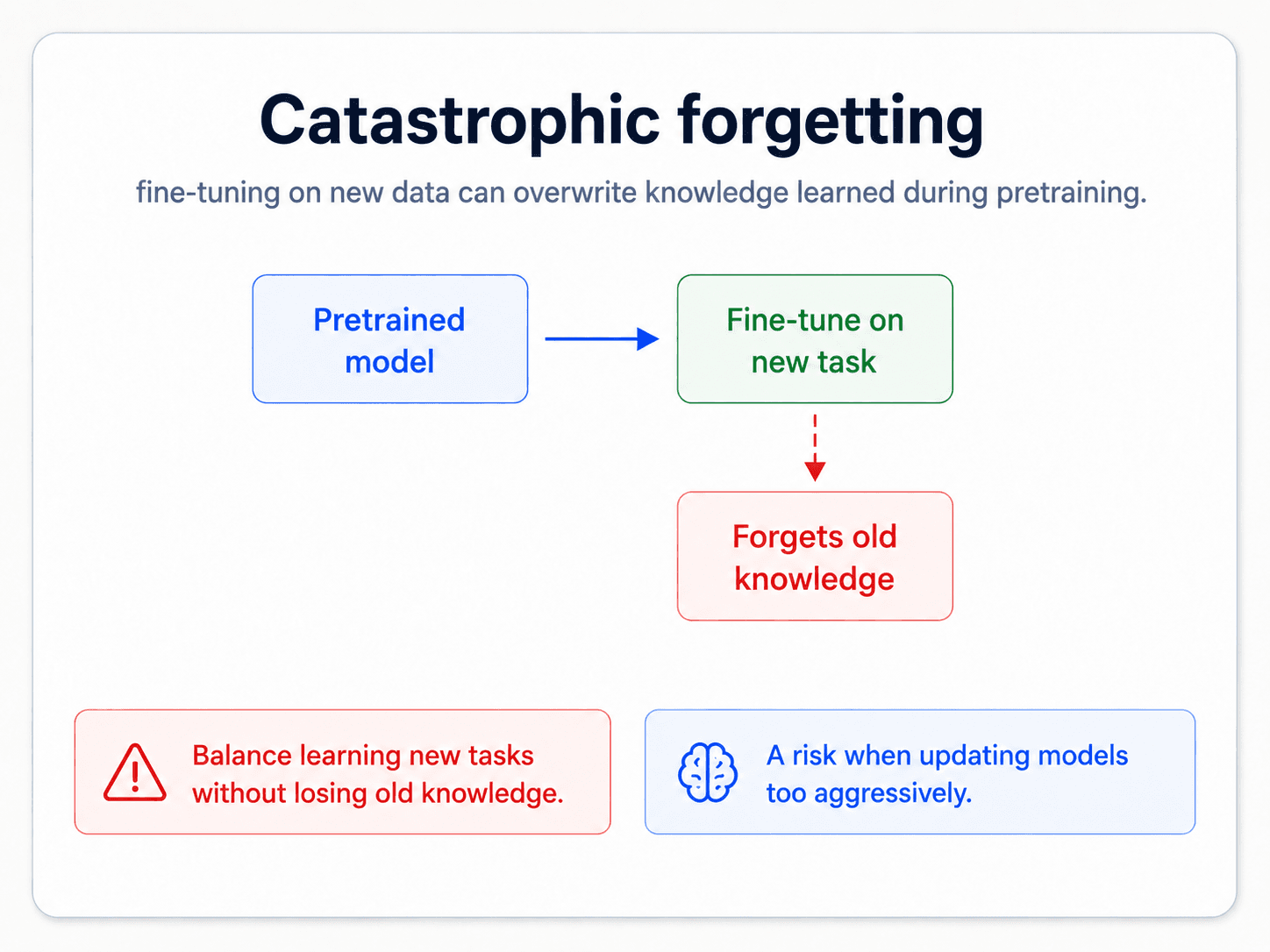
The fix is to fine-tune gently. That means: small learning rate, few epochs, watch for overfitting.
The learning-rate finder
Picking the learning rate is the single most important hyperparameter when fine-tuning. Get it wrong and the run is either useless or actively destructive.
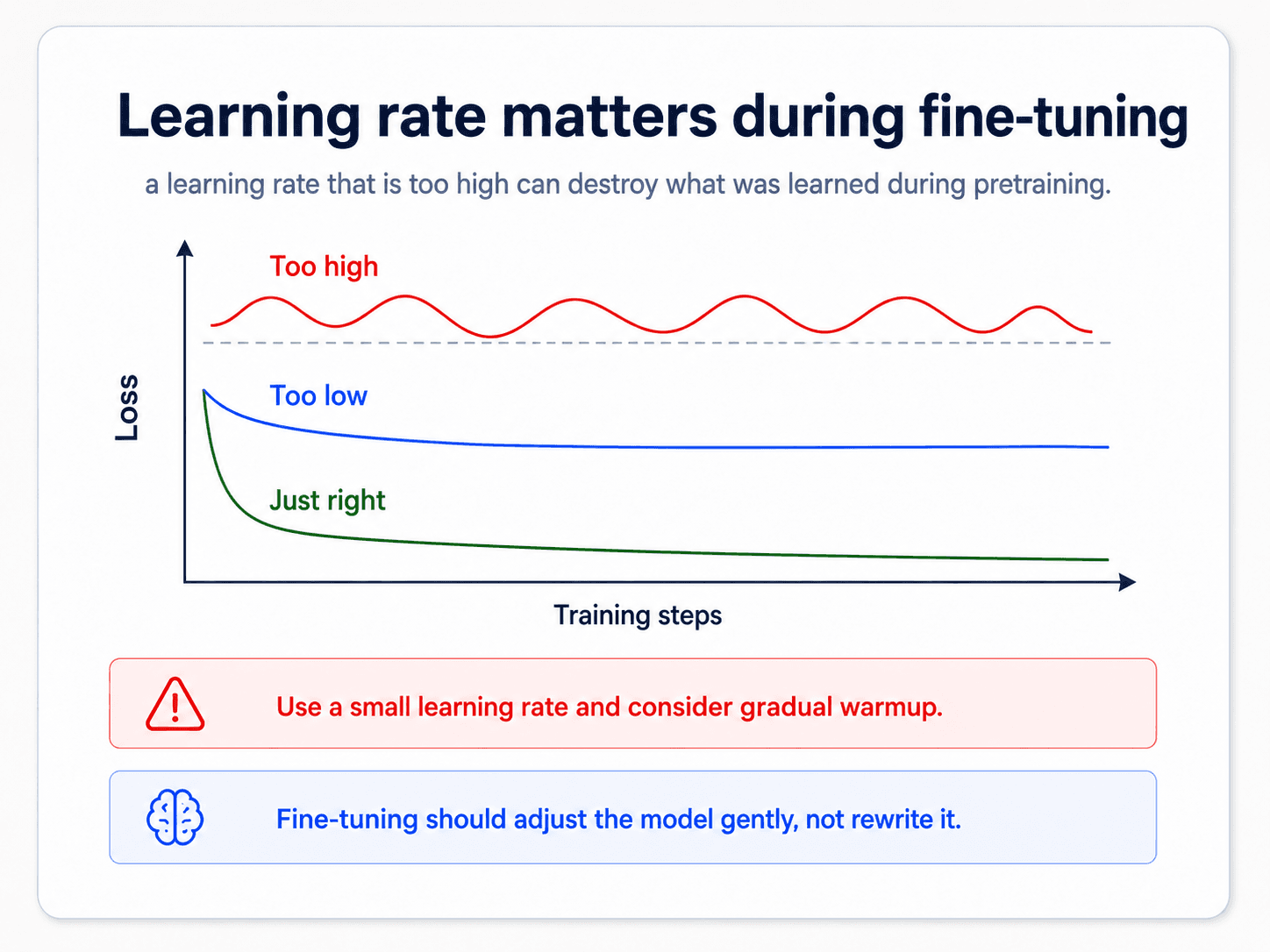
- Too high → the model can't learn. It jumps around the loss landscape and may diverge.
- Too low → the model technically learns, but slowly, and may not learn task-specific patterns at all.
The fastai trick to find the right one: train for a few mini-batches while gradually increasing the learning rate, plot loss vs LR, and pick the LR at the steepest descent.
Then watch one more thing: when training loss drops below validation loss, that is a strong sign of overfitting. Stop, or reduce the LR, before it gets worse.
Gradual unfreezing and discriminative learning rates
A transformer has many layers. They learn different things:
- Bottom layers learn the basics of the language — what a word is, what a noun is. You generally do not want to mess with these.
- Top layers learn task-specific patterns — how to combine words and meaning to do your task.
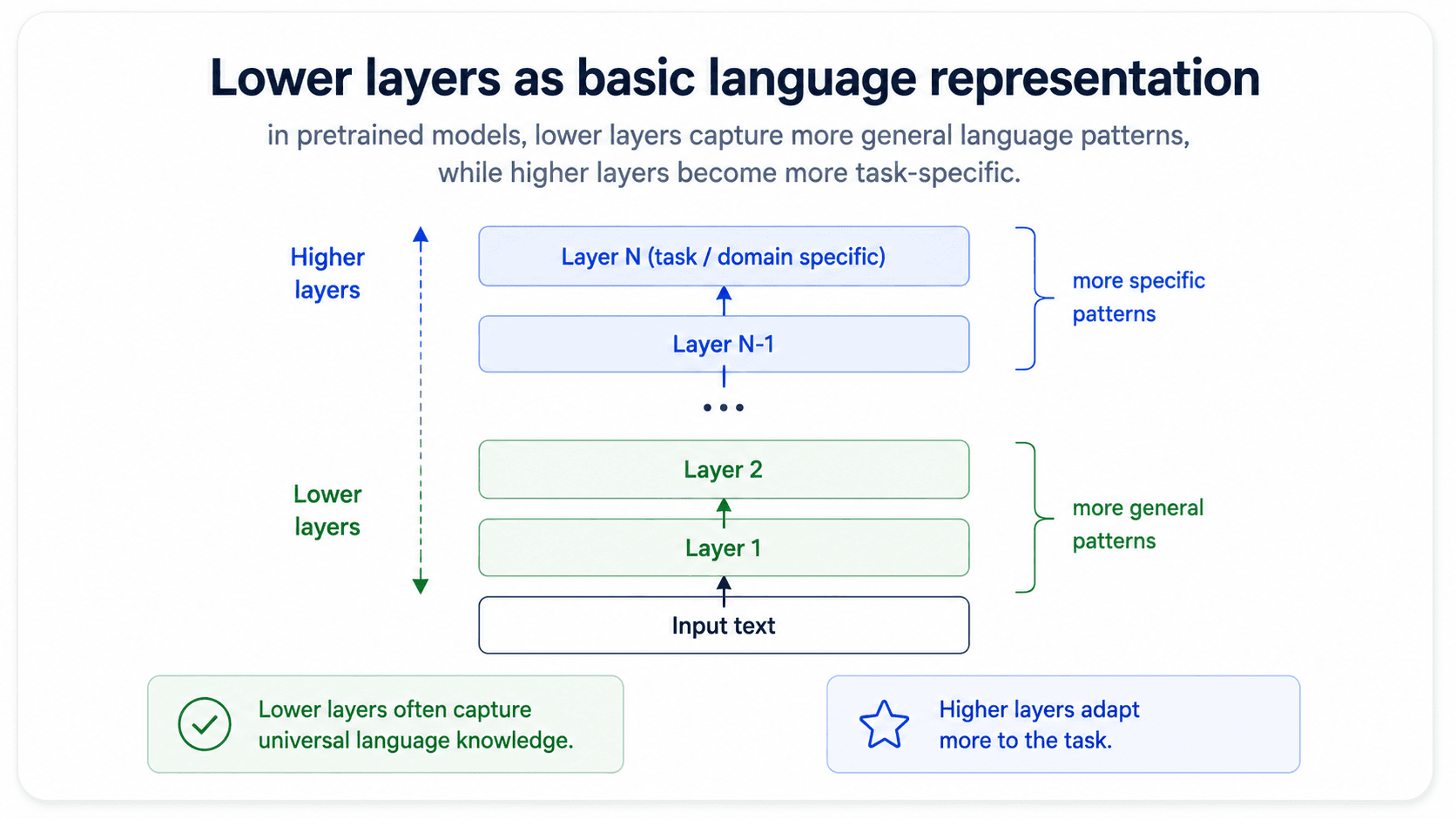
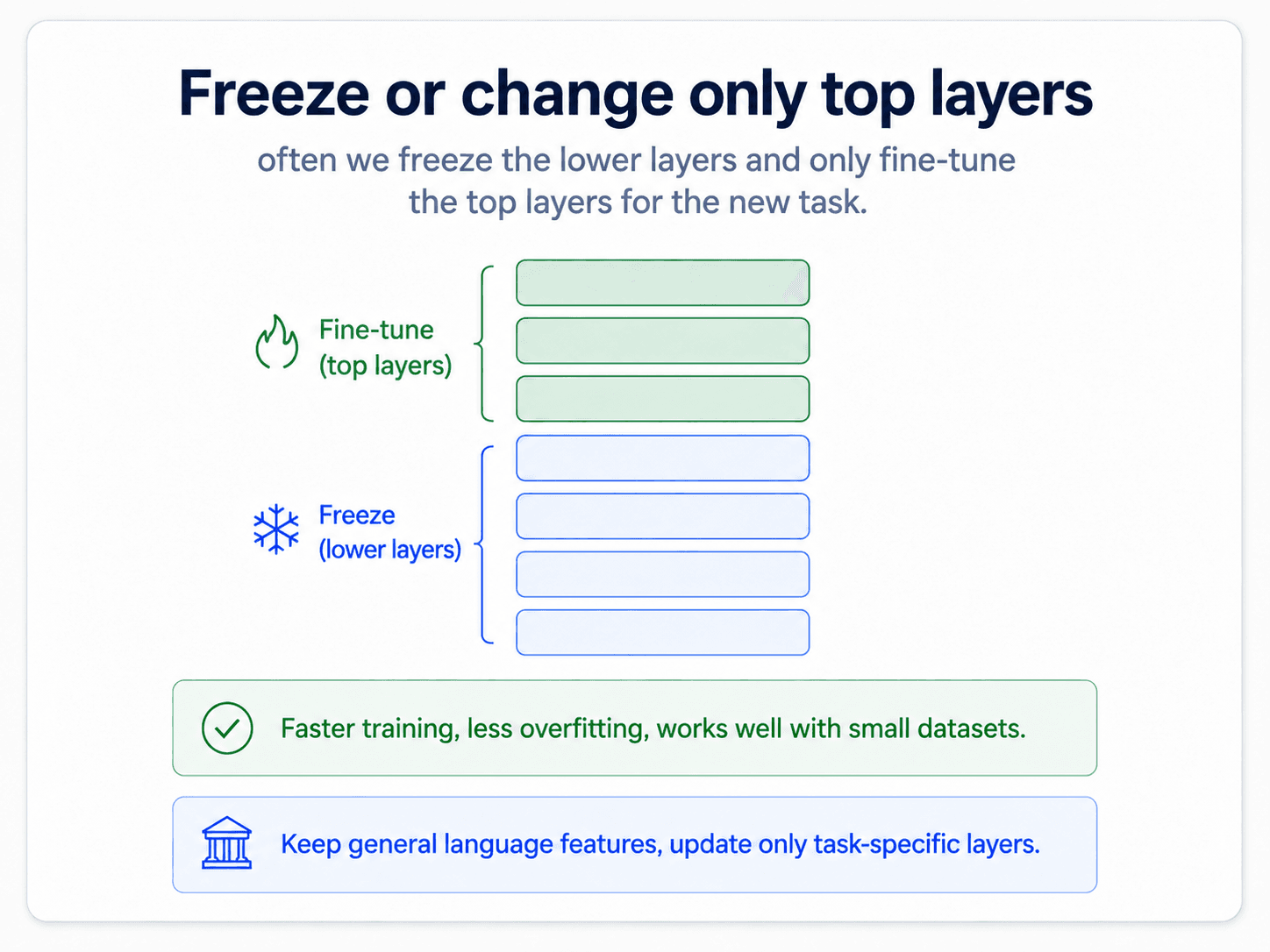
The practitioner workflow:
- Freeze everything except the classification head. Train just the head.
- Unfreeze the top transformer layer. Train with a learning rate.
- Unfreeze the next layer down. Train with a smaller learning rate (typically ~10× smaller).
- Repeat until performance stops improving.
This is discriminative learning rates — different layers get different LRs. The deeper the layer, the smaller the LR. It works because you trust the lower layers' weights more (they were learned on much more data) and want to perturb them less.
One-cycle policy and super-convergence
Within an individual fine-tuning run, the one-cycle learning-rate schedule is what fastai popularized. The learning rate starts small, ramps up to a peak, then decays back down — over the course of a single epoch.
With this schedule, the notes say that just one epoch is often enough. The phenomenon is called super-convergence and it is a real practical win.
Top losses and error analysis
After training, look at the examples the model gets most wrong — the top losses. Use them to debug. Look at where the model was confidently wrong, where the labels might be noisy, where the input might be malformed.
This is the unglamorous step that catches the bugs nobody else catches.
Hugging Face: where the models live
Practical infrastructure. Hugging Face is a repository of pretrained models and datasets. You download a model, write a few lines of code, and you have a working pipeline.
This is the practical answer to "how do I actually use one of these models?" — you do not train it yourself. You download it.
Removing the annotated dataset entirely
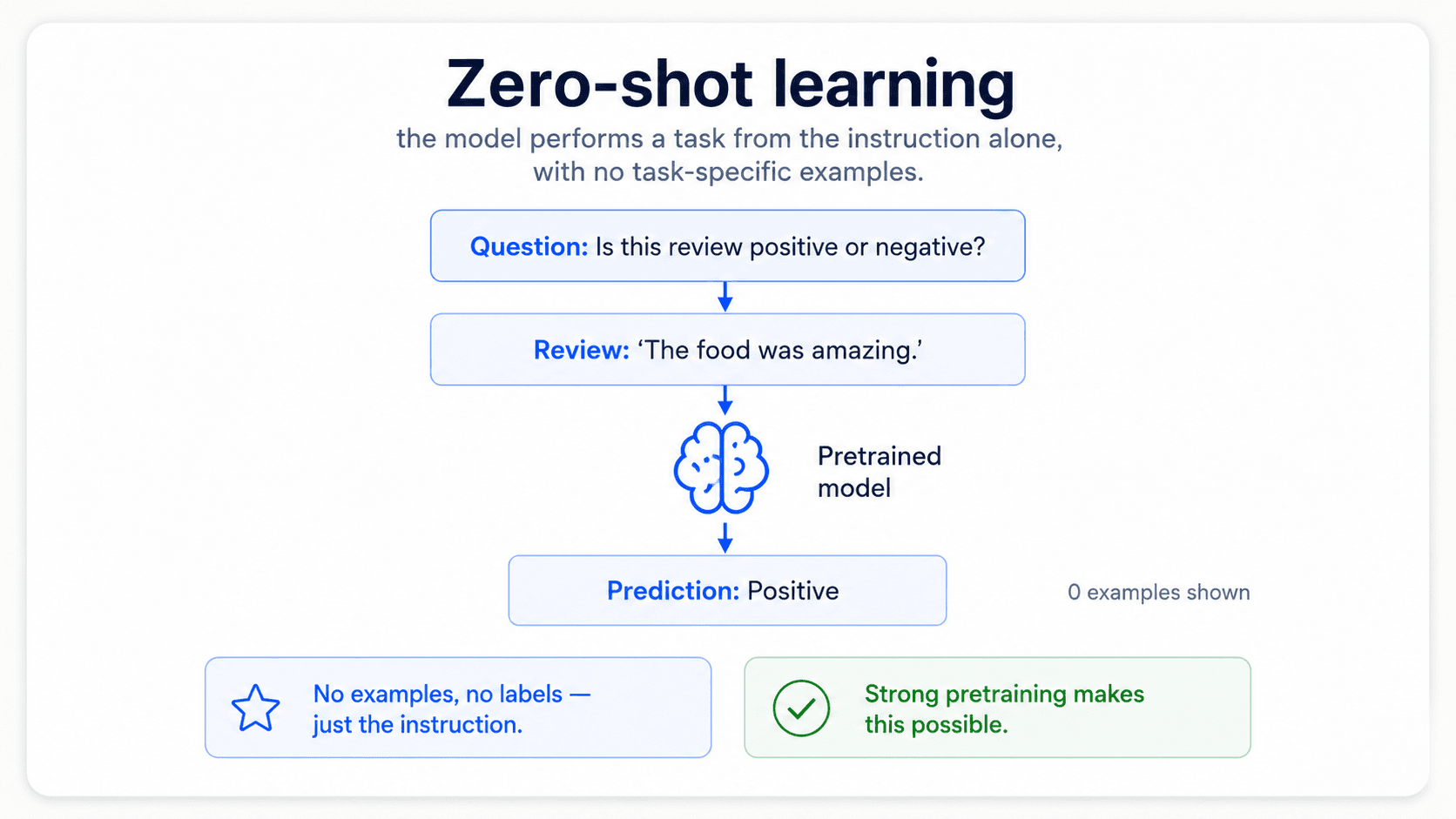
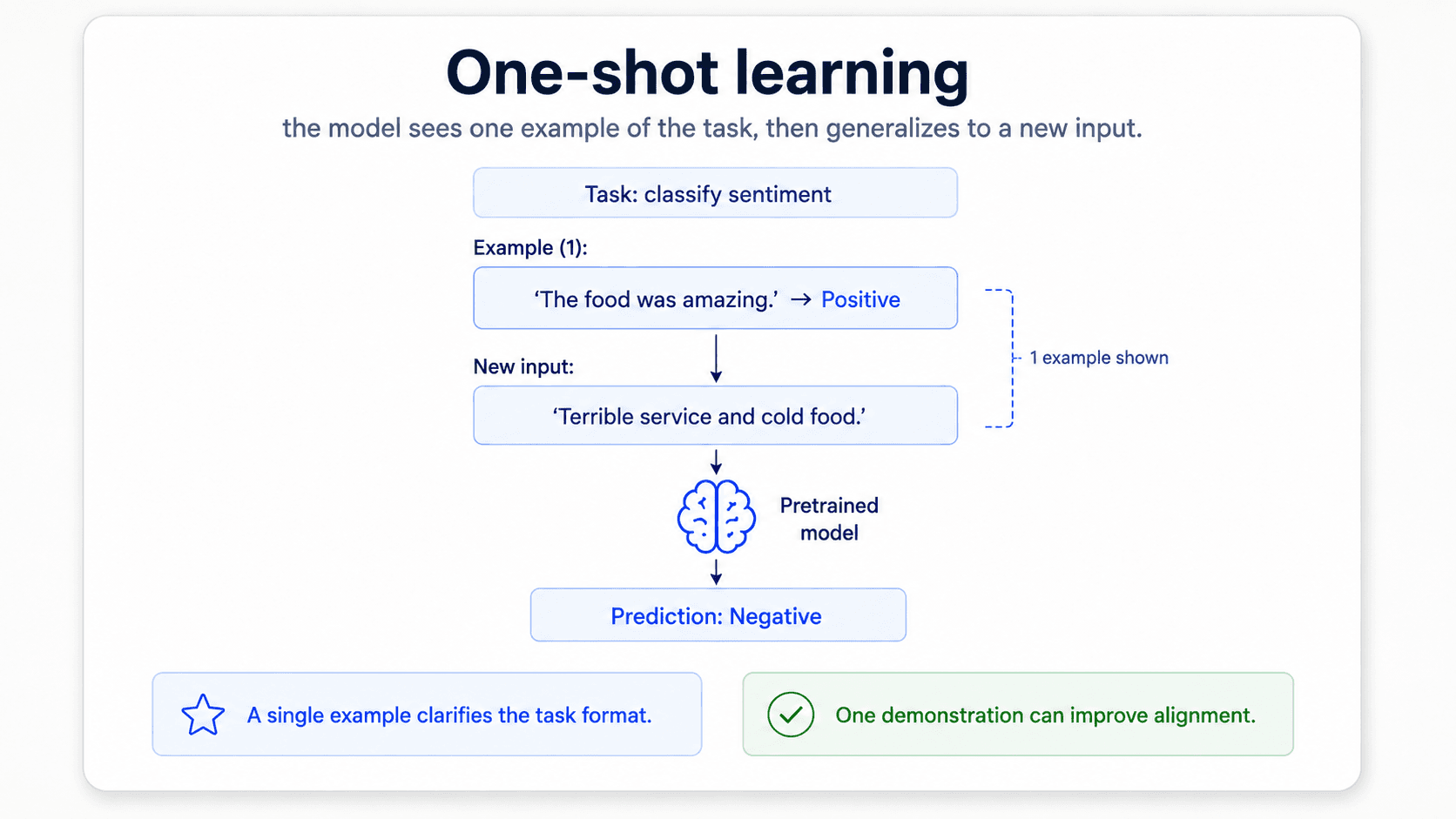
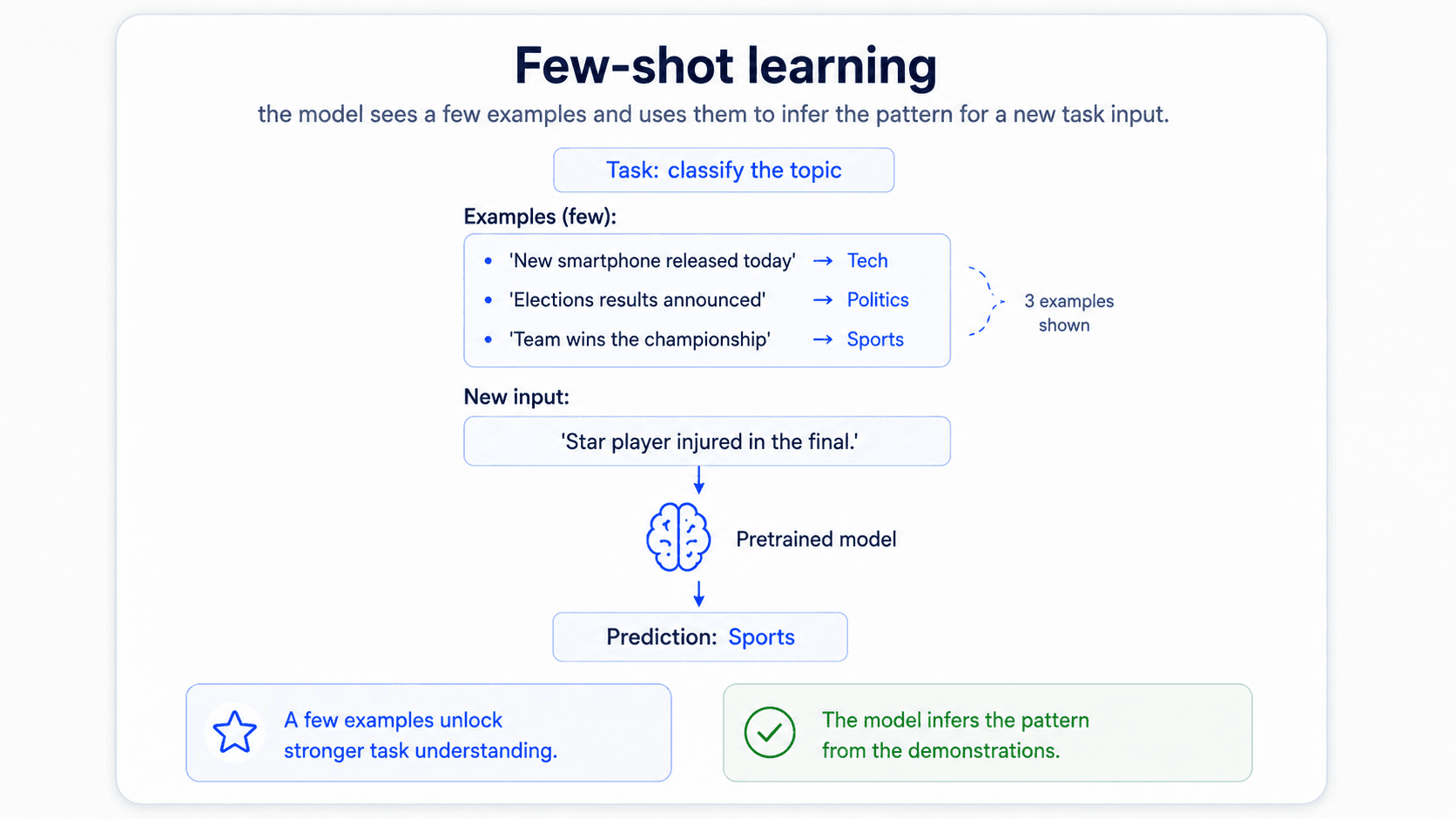
Everything we have built so far assumes you have some labelled data, even if it's tiny. With models large enough, you can drop that assumption too. There are three modes — and they're all the same trick: describe the task in natural language, optionally show the model a few examples, and let it answer.
Zero-shot — no examples at all
One-shot — show it one labelled example
Few-shot — a handful of examples in the prompt
The technical term for all three is in-context learning. The model doesn't change. The prompt does.
GPT-3 reframed NLP as text generation
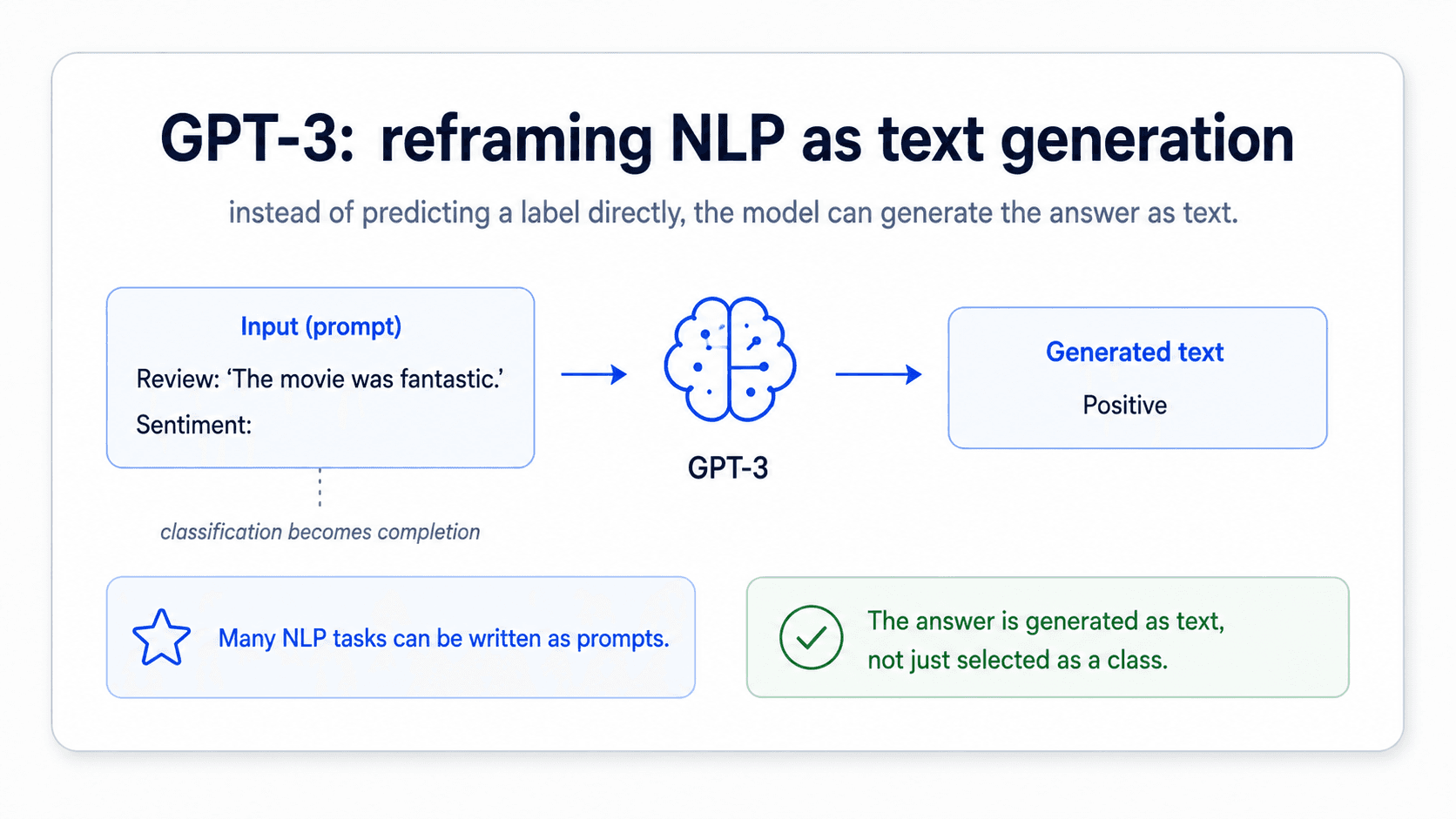
This is the moment NLP stopped being a collection of specialized pipelines and became a single thing — text-to-text. Everything is the same shape now: input text in, output text out, frozen model in the middle.
The catch: size is the feature
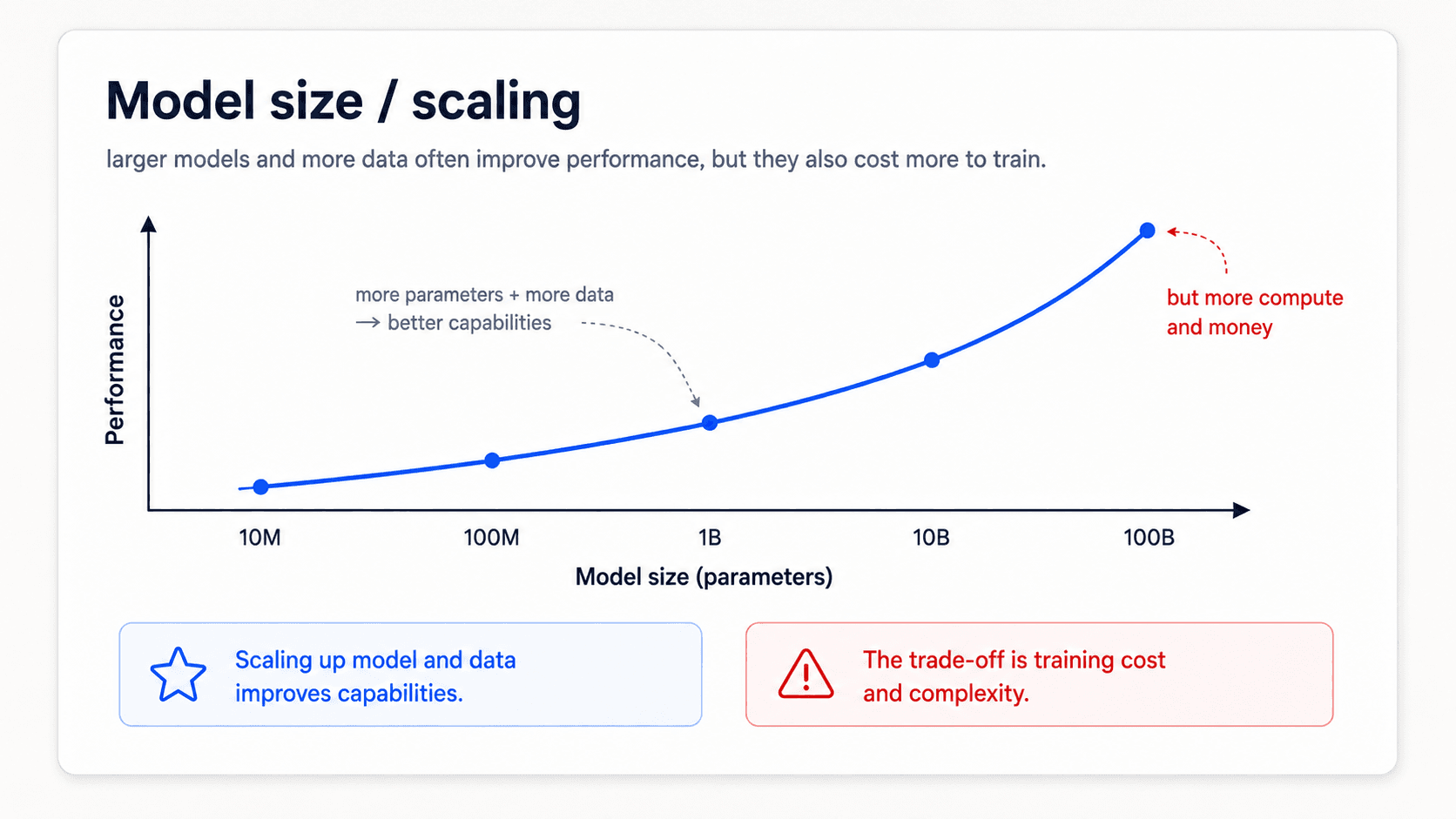
The key empirical finding from the GPT-3 paper is what makes any of this work — and it is uncomfortable for anyone who likes neat theoretical motivations:
The single most important feature is the size of the model.Few-shot and zero-shot are not techniques you can apply to any model. They are emergent behaviours that only show up at frontier scale.
Prompt engineering — the new craft
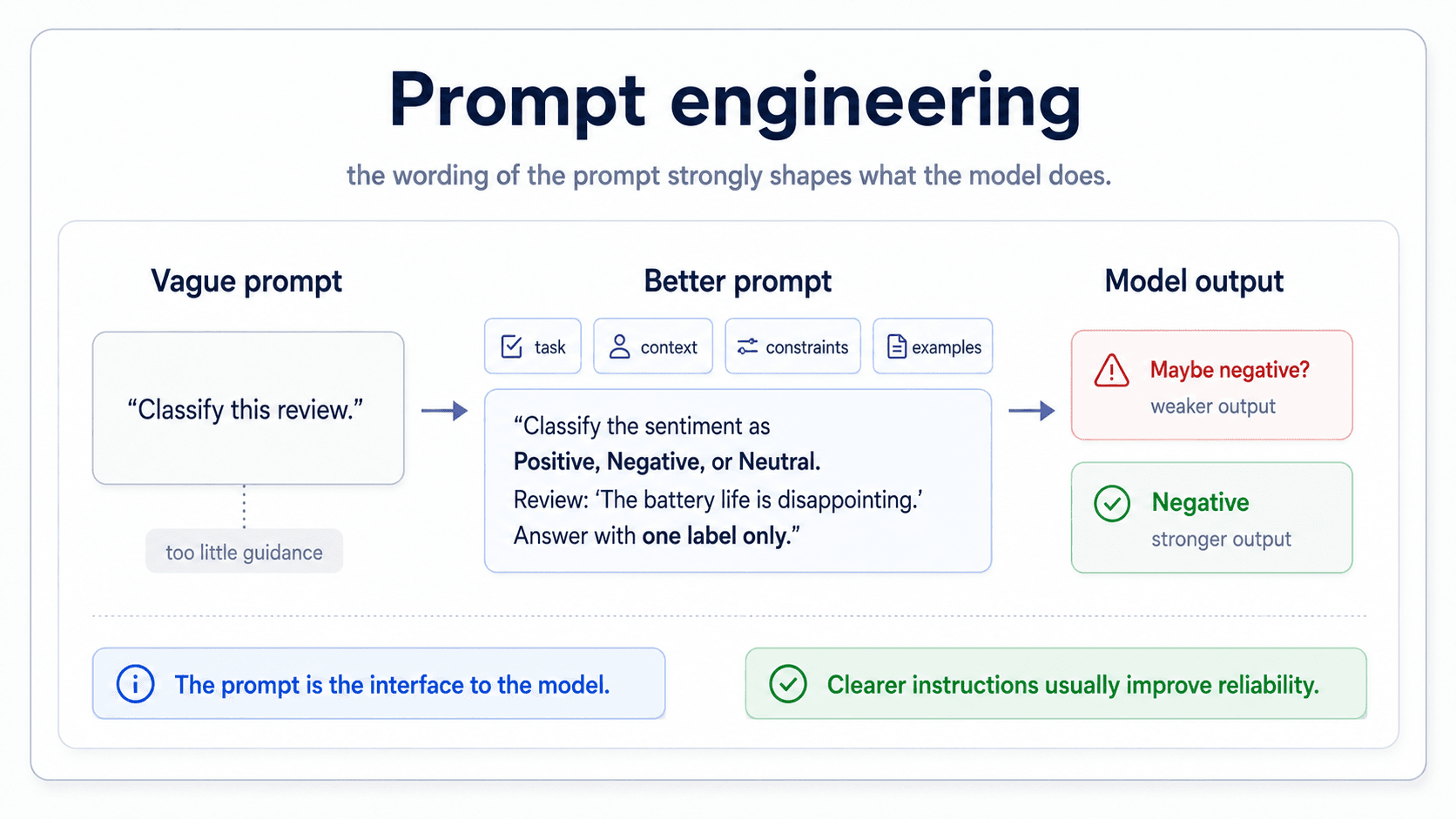
That insight reframes the field. It used to be that NLP expertise meant building better features and better architectures. Now there is a new strand — prompt engineering — where the expertise is in writing the right prompt to coax behaviour out of a frozen model. Whether you find that thrilling or depressing depends on the day.
The downsides — model complexity and money
The notes list two specific limitations of the frontier-LLM approach, and both are hard ceilings, not papercuts.
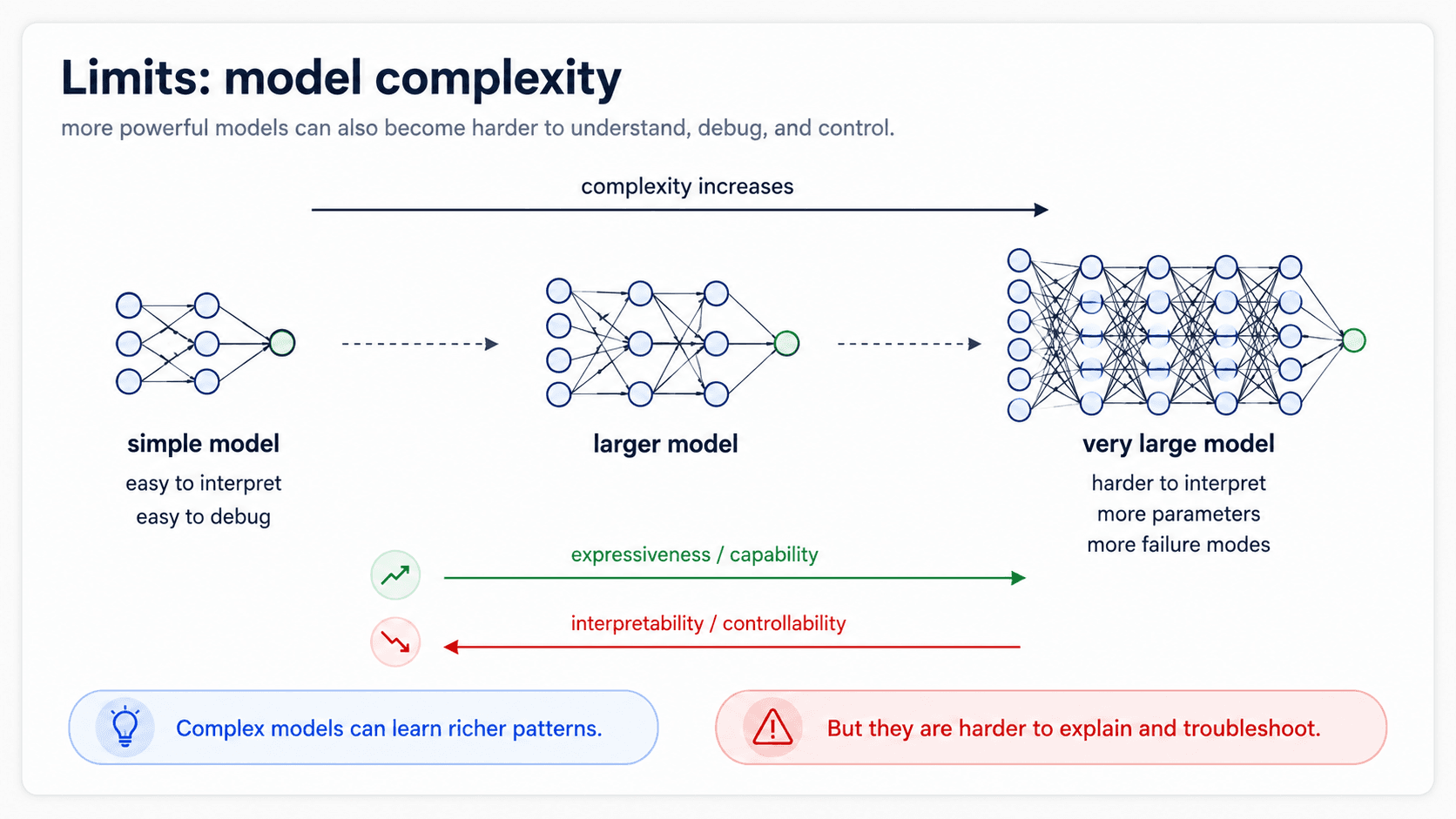
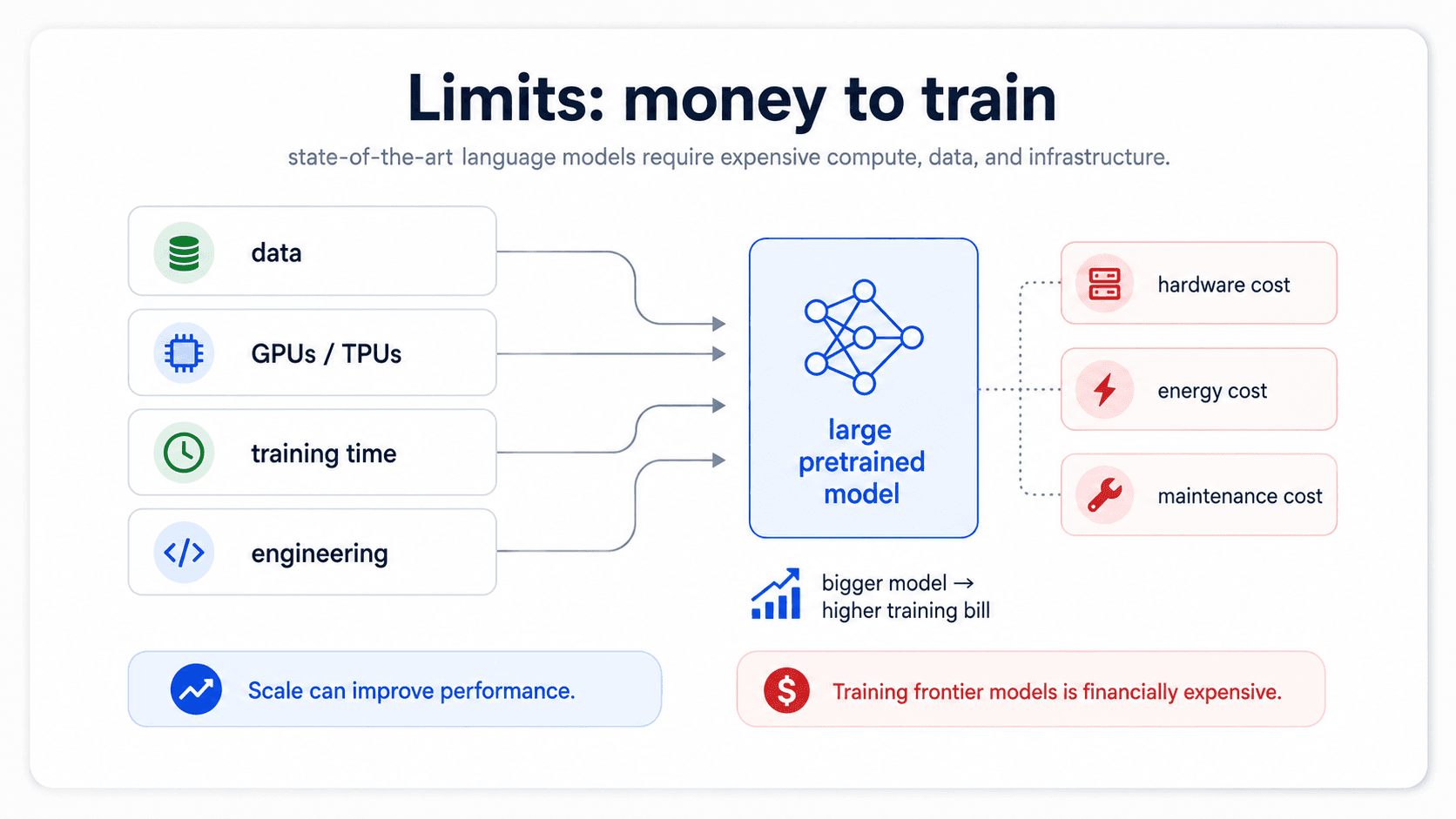
So zero-shot is a real option, but you are paying for it one prompt at a time.
When to use which deep-learning approach
The decision tree:
- Reasonable amount of labelled data? Fine-tune a pretrained BERT/RoBERTa from Hugging Face. Use one-cycle LR with discriminative LRs and gradual unfreezing. This is the workhorse.
- Tiny amount of labelled data? Either do unsupervised fine-tuning of the language model on your domain first (cheap — no labels needed), or use zero-shot with a frontier model.
- Very domain-specific text (medical, legal, code)? Run domain-adaptive language-model fine-tuning before the task fine-tuning. The cost is one extra step, the gain is a representation that "speaks" your domain.
- No labelled data at all? Zero-shot LLM, or fall back to the rules/Naïve Bayes options from Part 6.
What this connects to
You now have the deep-learning side of text classification: the data-hunger problem, the architectural moves (RNN → transformer with self-attention), language modelling as the representation, transfer learning as the workflow, and the practitioner gotchas (catastrophic forgetting, LR finder, gradual unfreezing, one-cycle, top losses) that make fine-tuning actually work.
The pattern that keeps showing up — pretrain a language model on huge unlabelled text, fine-tune on your task — is going to show up again in Part 8 (Information Retrieval), in Part 9 (Question Answering), and in Part 10 (Transformers & the Modern Stack). Once you have it in your head, the whole rest of modern NLP is variations on the same idea.
Next up: Part 8 — Information Retrieval. What happens when the user does not want a class label — they want the right document. Same plumbing underneath, different goal on top.