
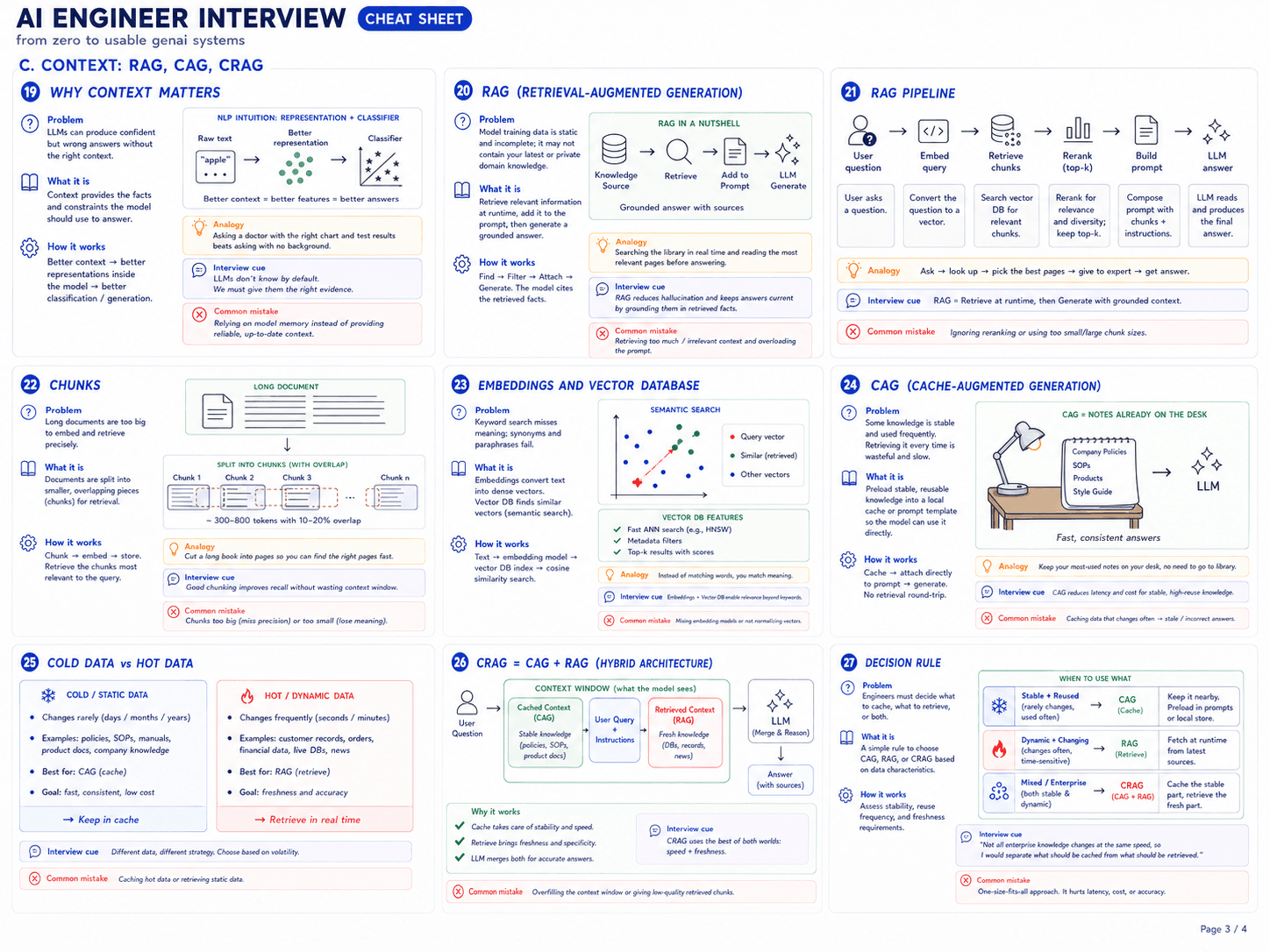
Table of Contents
- 1. Why RAG is the number-one GenAI interview topic
- 2. The RAG pipeline, end to end
- 3. Embeddings and vector databases
- 4. Chunking strategies
- 5. Retrieval methods: sparse, dense, hybrid
- 6. Reranking
- 7. Advanced patterns
- 8. RAG evaluation with RAGAS
- 9. Common RAG failure modes
- 10. A minimal LangChain RAG pipeline
- 11. Interview Q&A
- 12. What's next
- 13. Sources
Last update: July 2026. All opinions are my own.
Why RAG is the number-one GenAI interview topic
If you had to bet on a single topic your GFT interviewer will drill into, bet on RAG. Every production LLM system you will encounter in the wild is a RAG system in disguise — a chatbot on top of a knowledge base, a copilot grounded in internal docs, a customer-support agent that reads a ticket history before answering. The base LLM is a fluent brain with no memory of your business; retrieval is how you plug that brain into your data.
The reason RAG dominates interviews is that it forces you to reason across the whole stack at once. You need to talk about embeddings (representation learning), vector databases (systems), chunking (data engineering), retrieval (information retrieval), reranking (ML), prompt construction (LLM engineering) and evaluation (statistics). A single "walk me through your RAG pipeline" question is a stealth exam covering half of your technical stack.
This post is your one-stop reference. You will see the full pipeline, compare the main vector databases and embedding models, work through chunking and retrieval strategies, understand why reranking exists, meet the advanced patterns (HyDE, multi-query, parent-child) that keep getting asked about, and finish with the RAGAS evaluation framework. There is LangChain code, comparison tables, and a Q&A section at the end tuned for the questions you are most likely to hear next week.

1. The RAG pipeline, end to end
At its core, RAG is a two-lane system:
- The offline / ingest lane takes your documents, chunks them, embeds each chunk, and indexes those vectors into a vector store. This lane runs on a schedule (or on document change) and can afford heavyweight CPU work.
- The online / query lane takes a user question, embeds it, retrieves the top-k relevant chunks, optionally reranks them, packs them into a prompt, and asks the LLM to answer using only that context.
OFFLINE (ingest) ONLINE (query)
┌─────────┐ ┌────────┐ ┌──────┐ ┌───────┐ ┌────────┐ ┌────────┐ ┌─────────┐ ┌────────┐ ┌─────┐ ┌────────┐
│ Sources │→ │ Parse │→ │Chunk │→ │ Embed │→ │ Vector │ │ User │→ │ Embed │→ │Retrieve│→ │Rerank│→ │ LLM + │
│(PDF,web)│ │(extract│ │ │ │ │ │ store │←──────→│ query │ │ query │ │(top-k) │ │(opt) │ │ prompt │→ answer
└─────────┘ └────────┘ └──────┘ └───────┘ └────────┘ └────────┘ └─────────┘ └────────┘ └─────┘ └────────┘The reason to draw both lanes in an interview is that most people forget the ingest lane, then get stuck when the interviewer asks "so how does a new document actually enter the system?".

Why RAG exists
RAG solves four hard problems that plain LLMs can't:
- Hallucination. An LLM answering from parameters alone will confidently invent facts. Grounding it in retrieved passages measurably reduces this — and if the source is missing you can refuse to answer, which is often the correct behavior in regulated domains.
- Freshness. Model weights are frozen at training time. RAG lets you serve today's data (a policy update, a ticket that arrived an hour ago) without touching the model.
- Private / proprietary data. Your internal wiki, your Salesforce contracts, your customer support tickets — none of that is in the model's training set, and you can't send it to OpenAI to fine-tune on. RAG keeps the data in your vector store, only lifting the relevant chunk into the prompt at query time.
- Cost. Fine-tuning a 70B model is expensive, brittle, and needs re-doing every time the data changes. RAG is a one-time embedding cost plus per-query retrieval — often 100x cheaper for the same accuracy gain.
Interview angle. Expect a "RAG vs fine-tuning" question. The right answer is: fine-tune for behavior and style (tone, format, task specialization); use RAG for knowledge that changes or is too big to fit in weights. In practice you often do both — a fine-tuned model that also retrieves.
2. Embeddings and vector databases
An embedding is a dense vector (typically 384 to 3072 dimensions) that represents the meaning of a piece of text. Semantically similar texts land close together in vector space, so "what is the return policy?" and "how do I send this back?" have vectors with high cosine similarity even though they share no words.
Embedding models you should know
| Model | Provider | Dim | Notes |
|---|---|---|---|
text-embedding-3-large | OpenAI | 3072 (matryoshka) | Strong default, MTEB retrieval ~55%. Supports dimension truncation. |
text-embedding-3-small | OpenAI | 1536 | Cheap and fast. Good baseline for prototypes. |
embed-v3 / embed-multilingual-v3 | Cohere | 1024 | Best-in-class multilingual, strong retrieval. |
voyage-3-large | Voyage AI | 1024 | Currently top of MTEB retrieval leaderboard for API models. |
BGE-M3, bge-large-en-v1.5 | BAAI | 1024 | Open-weights, self-hostable, multilingual. |
all-MiniLM-L6-v2 | sentence-transformers | 384 | Tiny (80MB) — a solid CPU-friendly baseline. |
NV-Embed-v2, Qwen3-Embedding-8B | NVIDIA / Alibaba | 4096 / 4096 | Open-weight leaders (>70 MTEB) if you can host them. |
Rule of thumb for the interview: if you must pick one API model without more info, say text-embedding-3-large (OpenAI) — it's a strong retrieval score, cheap, and everyone recognizes it. For open-weights, say BGE-M3 or bge-large-en-v1.5.

Vector databases (the ones that come up)
| DB | Type | Best for | Watch out for |
|---|---|---|---|
| Pinecone | Managed SaaS | Serverless RAG at scale, zero infra work | Vendor lock-in, per-query cost |
| Weaviate | Open source + cloud | Native hybrid search, built-in modules | Heavier to self-host |
| Qdrant | Open source (Rust) | Fastest OSS option, great filtering | Fewer managed offerings |
| Milvus | Open source | Billion-vector scale, GPU indexes | Ops complexity |
| Chroma | Open source (Python) | Local dev, prototyping | Not for prod at scale |
| pgvector | Postgres extension | Under 10M vectors, already using Postgres | Not built for pure vector workloads |
Under the hood most of these use HNSW (Hierarchical Navigable Small World) as the approximate nearest neighbor index — a graph structure that gets you sub-linear search over billions of vectors. If asked, you should be able to say "ANN search with HNSW, tuning the ef_search parameter trades recall for latency."

Interview angle. If the interviewer says "which vector DB would you pick?", don't just name-drop. Ask about scale, whether they already run Postgres, whether they need hybrid search, and whether they can accept a managed service. Then justify one choice — the reasoning matters more than the answer.
3. Chunking strategies
Chunking is where most RAG systems live or die, and it's the least glamorous part. Feed the retriever chunks that are too small and you lose context; too big and the embedding averages out the meaning and you retrieve garbage.
The five you need to know
| Strategy | How it works | When to use |
|---|---|---|
| Fixed-size | Split every N characters/tokens with fixed overlap. | Baseline. Simple and predictable, ignores meaning. |
| Recursive character | Try to split on \n\n, then \n, then ., then space, until chunk fits. LangChain default. | Most text — respects paragraph and sentence boundaries. |
| Sliding window | Overlapping windows (e.g. 512 tokens, 128 overlap). | Preserves cross-boundary context for narrative text. |
| Semantic | Embed each sentence, start a new chunk when consecutive-sentence similarity drops below a threshold. | Best accuracy, expensive to compute. Great for technical docs. |
| Document-aware | Use structure (Markdown headers, HTML tags, code fences, tables) to split. | Wikis, code repos, structured PDFs. |

A working default for most workloads is: recursive character splitter, 512 tokens per chunk, 15–20% overlap. That's what LangChain's RecursiveCharacterTextSplitter gives you and it's rarely wrong to start there.
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # tokens (via tiktoken) or chars
chunk_overlap=80, # ~15% overlap
separators=["\n\n", "\n", ". ", " ", ""],
)
chunks = splitter.split_documents(docs)Interview angle. If asked "how do you pick chunk size?", the answer is: it depends on the density of information. Legal/technical prose wants smaller chunks (256–512 tokens) so you don't dilute the signal; narrative documents can handle larger (1024). Always tune with an eval set — do not guess.
Parent-child (a.k.a. small-to-big) chunking
A trick that works surprisingly well: embed and search on small child chunks (~200 tokens) for precision, but return the parent chunk (~1500 tokens) to the LLM for context. LangChain has a ParentDocumentRetriever for exactly this. Reported gains: 15–30% accuracy on queries that need broad context.
4. Retrieval methods: sparse, dense, hybrid
Sparse retrieval (BM25 / TF-IDF)
Classic keyword retrieval, no embeddings. BM25 scores a document by how often the query terms appear, adjusted for document length and inverse document frequency. It's a strong baseline and unbeatable on exact-match queries — product codes (SKU-4471X), named entities, rare technical terms. If someone searches for "GDPR Article 17" and your dense retriever returns "data protection principles" instead, that's the failure mode BM25 fixes.
Dense retrieval (embedding similarity)
Embed the query with the same model you embedded the corpus, then cosine-similarity search the vector index. This is what "semantic search" usually means. It handles paraphrases and synonyms — "how do I cancel?" retrieves "termination procedure" — but can miss exact rare-term matches because the embedding averages meaning across the sentence.
Hybrid retrieval
Run both, then fuse the ranked lists. The dominant fusion technique is Reciprocal Rank Fusion (RRF) — dead simple, and it works:
RRF is score-agnostic (it operates on ranks, so you don't need to normalize wildly different score scales from BM25 vs cosine), and it rewards documents that both rankers agree on. Reported gain on the WANDS e-commerce benchmark: ~7.4% NDCG lift over either alone.

from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
bm25 = BM25Retriever.from_documents(chunks); bm25.k = 10
dense = vectorstore.as_retriever(search_kwargs={"k": 10})
hybrid = EnsembleRetriever(
retrievers=[bm25, dense],
weights=[0.4, 0.6], # weights become RRF weights internally
)| Method | Handles paraphrase | Handles exact terms | Cost | Notes |
|---|---|---|---|---|
| Sparse (BM25) | Weak | Excellent | Very cheap | Strong baseline, always keep it |
| Dense | Excellent | Weak on rare tokens | Moderate | Needs an embedding model |
| Hybrid | Excellent | Excellent | Sum of both | Almost always the right choice in prod |
Interview angle. "Would you use pure vector search in production?" The answer they want to hear is: rarely. Almost every real system is hybrid because production queries are a mix of "what is our vacation policy" (dense wins) and "show me clause 4.2.7" (sparse wins).
5. Reranking
Even with hybrid retrieval, your top-k is noisy. This is where a cross-encoder reranker comes in. Where a bi-encoder embedding model encodes the query and document separately and then measures similarity, a cross-encoder feeds the pair [query, document] through a single transformer, letting every query token attend to every document token. It's much more accurate — and much more expensive, which is why you only run it on the top ~50 candidates, not the whole corpus.

Standard pipeline: retrieve top 50 with hybrid search (cheap), rerank to top 5 with a cross-encoder (accurate), pass those 5 to the LLM.
The rerankers worth naming
- Cohere Rerank 3 — API, $1 per 1k queries, best-in-class quality with no infra work.
- BGE Reranker v2-m3 — open weights, ~278M params, runs on a single GPU or even CPU for small batches. The default pick if you self-host.
- Jina Reranker v2 — another open option, strong multilingual.
ms-marco-MiniLM-L-6-v2— the classic sentence-transformers cross-encoder. Tiny, fast, still a solid baseline.
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("BAAI/bge-reranker-v2-m3")
pairs = [(query, doc.page_content) for doc in top50]
scores = reranker.predict(pairs)
top5 = [doc for _, doc in sorted(zip(scores, top50), reverse=True)[:5]]Interview angle. "Why not use a cross-encoder for the initial retrieval?" Because it's O(N) in corpus size — you'd have to score the query against every one of your millions of chunks. Bi-encoders precompute chunk embeddings once and use ANN indexes; cross-encoders can't be precomputed because the score depends on the pair.
6. Advanced patterns
Once the basics are wired up, these are the techniques that show up in senior interviews:
HyDE — Hypothetical Document Embeddings
From Gao et al., 2022. The idea: instead of embedding the user's short question (which lives in "question space"), first ask a small LLM to write a hypothetical answer, then embed that. The generated answer, even if partially wrong, sits much closer in embedding space to the real answers in your corpus than the raw question does.
Query: "What are the side effects of ibuprofen?"
↓ LLM generates hypothetical answer
Hyp doc: "Ibuprofen commonly causes stomach upset, heartburn,
and in rare cases kidney issues..."
↓ Embed hypothetical doc
↓ Retrieve from vector store
Real docs about ibuprofen side effects → LLM → grounded answerReported wins on TREC and BEIR: HyDE beats unsupervised Contriever and rivals fine-tuned retrievers, all zero-shot.
Multi-query retrieval
Ask the LLM to generate 3–5 paraphrases of the query, retrieve for each, deduplicate the union. Covers vocabulary mismatch: "cheap flight to Madrid" and "affordable Madrid ticket" and "budget Iberia fare" all pull in overlapping-but-different chunks. LangChain has MultiQueryRetriever built in.
Query expansion / rewriting
A superset of the above — the LLM rewrites the raw query into a cleaner, more retrievable form (adds context, expands acronyms, decomposes multi-hop questions). Particularly important in chat, where the raw user turn is often "and what about that?" — meaningless without conversation history.
Parent-child (small-to-big)
Covered above under chunking. Worth mentioning again because it's the single most effective "advanced" trick and takes ten lines to implement.
7. RAG evaluation with RAGAS
The single biggest mistake juniors make is shipping a RAG pipeline without a way to measure it. The framework the industry has converged on is RAGAS — four metrics that pull apart retrieval quality from generation quality.
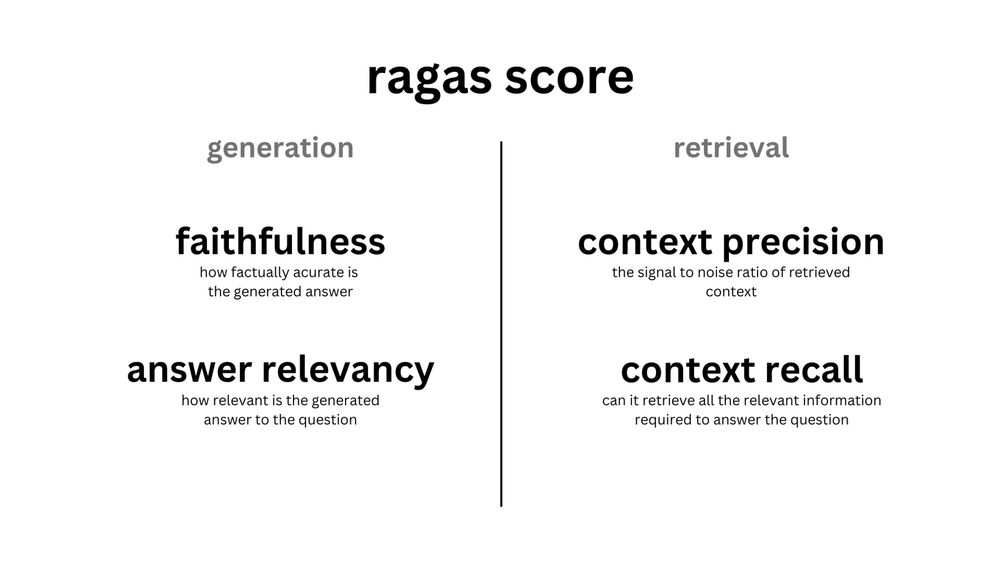
| Metric | What it measures | Failure mode it catches |
|---|---|---|
| Context precision | Of the retrieved chunks, how many are actually relevant? | Retriever pulls in noise |
| Context recall | Of the info needed to answer, how much was retrieved? | Retriever misses key chunks |
| Faithfulness | Are the claims in the answer supported by the retrieved context? | LLM hallucinates despite good context |
| Answer relevancy | Does the answer address the actual question? | LLM goes off-topic |
The first two evaluate the retriever; the last two evaluate the generator. This split is the key insight — when your system is failing, RAGAS tells you where. Low context recall means fix chunking or retrieval; high context recall but low faithfulness means the LLM is ignoring the context or hallucinating.
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision, context_recall
from datasets import Dataset
data = Dataset.from_dict({
"question": ["How do I cancel my subscription?"],
"answer": ["Go to Settings → Billing → Cancel."],
"contexts": [["To cancel, open Settings, click Billing, then Cancel Subscription."]],
"ground_truth": ["Navigate to Settings, then Billing, and select Cancel."],
})
result = evaluate(data, metrics=[
faithfulness, answer_relevancy, context_precision, context_recall,
])
print(result) # e.g. {'faithfulness': 1.0, 'answer_relevancy': 0.95, ...}Interview angle. Be ready for "how would you evaluate a RAG system?". The wrong answer is "we look at some outputs and see if they look good". The right answer names the four RAGAS metrics, splits retrieval vs generation, and mentions building a small (100–500) hand-labeled eval set.
8. Common RAG failure modes
Interviewers love this question because it separates people who have shipped RAG from people who have only read about it.
- Irrelevant retrieval. Top-k doesn't contain the answer. Fix: better chunking, hybrid search, reranking, larger k, or query rewriting.
- Lost in the middle. Liu et al., 2023 showed LLMs pay much more attention to the beginning and end of long contexts than the middle. If you cram 20 chunks into a prompt, the ones in positions 8–13 might as well not exist. Fix: rerank so the best chunk is at position 1 (or last), and keep context short.

- Hallucination despite context. The retrieved chunks are correct but the LLM ignores them and invents an answer anyway. Fix: instruct the model to answer only from the context, cite chunk IDs, and refuse if the answer isn't there.
- Contradictory chunks. Retriever returns two chunks that disagree (e.g. an old policy and a new one). Fix: recency-aware retrieval, metadata filters, or a reconciliation step.
- Query drift in chat. Follow-up turns lose the original topic. Fix: rewrite the query using the conversation history before retrieval.
- Chunk boundary loss. The answer is split across two adjacent chunks and neither has the whole thing. Fix: overlap, parent-child chunking, or bigger chunks.
9. A minimal LangChain RAG pipeline
The one you should be able to whiteboard in an interview:
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 1. INGEST (offline)
docs = PyPDFLoader("handbook.pdf").load()
chunks = RecursiveCharacterTextSplitter(
chunk_size=512, chunk_overlap=80
).split_documents(docs)
vectorstore = Chroma.from_documents(
chunks, embedding=OpenAIEmbeddings(model="text-embedding-3-large")
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
# 2. QUERY (online)
prompt = ChatPromptTemplate.from_template(
"Answer the question using ONLY the context below.\n"
"If the answer isn't in the context, say you don't know.\n\n"
"Context:\n{context}\n\nQuestion: {question}"
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def format_docs(docs):
return "\n\n".join(d.page_content for d in docs)
rag = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
print(rag.invoke("What is our parental leave policy?"))That's ~25 lines and it's a real, working RAG system. To level it up for production you would add: hybrid retrieval, a reranker between retriever and format_docs, metadata filters, source citations, streaming, and a RAGAS evaluation loop.
10. Interview Q&A
Q1. Walk me through a RAG system end to end. A. Two lanes. Offline: parse documents, chunk them (recursive character splitter, ~512 tokens, ~15% overlap), embed each chunk with an embedding model, upsert into a vector store. Online: embed the query, run hybrid (BM25 + dense) retrieval for top-50, rerank with a cross-encoder to top-5, stuff those into a prompt template with clear "answer only from context" instructions, hit the LLM, return the answer with citations. Evaluate continuously with RAGAS.
Q2. RAG or fine-tuning? A. Fine-tune for behavior (tone, format, task specialization). RAG for knowledge (facts that change, private data, huge corpora that can't fit in weights). In practice, both — a fine-tuned model that also retrieves. RAG is almost always cheaper and safer to start with.
Q3. Which vector database and why? A. Depends on scale and existing infra. Under 10M vectors and already running Postgres → pgvector, no new system to operate. Fully managed at scale → Pinecone. Open-source, self-hosted, want speed → Qdrant. Need billion-scale with GPU indexes → Milvus. Local prototyping → Chroma. All of them use HNSW under the hood so the algorithmic difference is small; the choice is really about ops.
Q4. How do you choose chunk size? A. Depends on information density. Dense technical text — 256–512 tokens. Narrative — 1024. Always overlap 10–20%. But tune it with an eval set; don't guess. And consider parent-child chunking: embed on small chunks for precision, return large chunks for context.
Q5. Sparse, dense, or hybrid? A. Hybrid, almost always. Sparse (BM25) wins on exact-match — product codes, named entities, rare tokens. Dense wins on paraphrase and synonyms. Real queries are a mix, so fuse both with Reciprocal Rank Fusion. Pure dense misses "what's SKU-4471X?"; pure sparse misses "how do I cancel my subscription?" when the doc says "termination procedure".
Q6. Why do you need a reranker if you already have retrieval?
A. The retriever is a bi-encoder — query and document embedded separately, then compared. Fast but coarse. A cross-encoder reranker feeds [query, doc] through one transformer, so every query token can attend to every doc token — much more accurate but O(N), so you can't run it on the whole corpus. Standard pipeline: retrieve 50 cheap, rerank to 5 accurate.
Q7. What is HyDE and when does it help? A. Hypothetical Document Embeddings, Gao et al. 2022. Instead of embedding the short user question, you ask an LLM to write a fake answer first, then embed that. The fake answer lives in the same "answer space" as your corpus, so nearest-neighbor search retrieves better documents. Especially helpful zero-shot (no fine-tuned retriever) and for short/ambiguous queries. Downsides: extra LLM call adds latency, and if the hypothesis is very wrong you retrieve badly.
Q8. What is "lost in the middle" and how do you avoid it? A. Liu et al. 2023 showed LLMs attend most to the start and end of long contexts and least to the middle. So stuffing 20 chunks into the prompt hides the most useful ones if they land in position 10. Mitigation: keep context short, rerank so the highest-scoring chunk is at position 1 or last, and don't rely on "more context = better answer".
Q9. How do you evaluate a RAG system? A. RAGAS framework: four metrics splitting retrieval from generation. Context precision and context recall grade the retriever (are we pulling the right chunks, are we pulling all of them). Faithfulness and answer relevancy grade the generator (is the answer grounded in the context, does it answer the question). Build a 100–500 example labeled eval set. Track the four metrics in CI; regressions on any one point at a specific failure.
Q10. What are the most common RAG failure modes in production? A. (1) Retrieval misses — bad chunking or vocabulary mismatch, fix with hybrid + reranking. (2) Lost in the middle — context too long, fix with reranking and shorter prompts. (3) Hallucination despite context — LLM ignores retrieved passages, fix with stricter prompting, citations, and refusal instructions. (4) Query drift in chat — fix with query rewriting using history. (5) Contradictory chunks (e.g. old vs new policy) — fix with metadata filters and recency scoring.
What's next
Retrieval gives your LLM knowledge. Memory, up next in Part 8, gives it continuity — how to keep track of what the user just said, what they said last week, and what the agent has already tried in the current run. It's the second half of "grounding" and it comes up almost as often as RAG in interviews.
If you want the classical information-retrieval foundations underneath all of this — BM25, TF-IDF, precision/recall/nDCG, inverted indexes — go back to NLP Part 8: Information Retrieval. Modern RAG is IR with embeddings glued on; the fundamentals still apply.
Sources
- HyDE: Precise Zero-Shot Dense Retrieval without Relevance Labels — Gao et al. 2022 (arXiv)
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al. 2023 (arXiv)
- RAGAS official docs — metrics reference
- LangChain — Build a RAG agent (official)
- LangChain — ParentDocumentRetriever
- Pinecone — Chunking Strategies for LLM Applications
- Weaviate — Hybrid Search Explained
- Cohere — Rerank API
- BGE Reranker v2-m3 (Hugging Face)
- NVIDIA — RAG 101: Demystifying Retrieval-Augmented Generation Pipelines
- MTEB Leaderboard (Hugging Face)
- Vector Database Comparison 2026 — Reintech
- Reciprocal Rank Fusion — original paper (Cormack et al.)