
Table of Contents
- 1. NLP, in one sentence
- 2. What you can actually do with NLP
- 3. The restaurant menu insight
- 4. Where NLP actually sits
- 5. Scope of this series
- 6. The 5 levels of NLP
- 7. Why NLP is hard (or: why language is built against us)
- 8. Is statistics + ML enough?
- 9. The knowledge-based approach (and the pendulum)
- 10. Where the field actually is right now
- 11. Why NLP, and why now?
- 12. The cognitive chasm
- 13. What's next
Last update: June 2026. All opinions are my own.
NLP from Scratch · Part 1/10
📋 In a hurry? Read the one-page cheat sheet — the 5-level ladder, the hard problems, and the field map, condensed for fast revision (or ⌘ P to print it).
If you can read a report and you can't tell whether a human or a computer wrote it — the computer is intelligent. That's the Turing Test, and it's basically the whole reason this field exists.
A small disclaimer before anything else: NLP is not Neuro Linguistic Programming. I know. Same letters, very different thing. The one we care about is Natural Language Processing — how computers process the language that humans actually speak, in contrast to artificial languages like Java or Python.
This is Part 1 of a series. Before we touch any tokenizers, embeddings, or transformers, we need a map of the territory — what NLP is, what it can do, what it can't do yet, and the 5 levels every NLP system has to climb. Once you have the map, every later post fits somewhere on it.
NLP, in one sentence
Imagine you're working with Python. You want to load a dataset. Today you write pd.read_csv("data.csv"). Back in the 50s and 60s, people asked: wouldn't it be better to just tell the computer "read the file" — in English? That question is basically the original motivation for NLP.
The formal definition:
🔑 Natural Language Processing is the automatic analysis and understanding of natural language for the communication between computers and humans.
The "communication" half is still true — that's what powers chatbots, voice assistants, translation. But it's not the whole story. We also use NLP to understand — to extract meaning, signal, and structure from text that nobody is going to read by hand.
What you can actually do with NLP
The catalogue of business problems NLP gets pointed at is wider than most people realise:
- Question Answering. You write a question in English, you get an answer. Internally — pulling from a database of reviews, documents, or tickets. Google does this. Your support team probably should.
- Machine Translation. Google Translate. DeepL. The thing that turns "buen provecho" into "enjoy your meal" without anyone having written a Spanish-to-English dictionary by hand.
- Text or Language Generation. Phone keyboard suggestions. Gmail Smart Compose. And — the more advanced version — full reports written by a system, where you can't reliably tell whether a human or a computer produced them. That last part is the Turing Test in action: if you can't distinguish the output, the system is intelligent.
- Fake News Detection.
- Summarization.
- Information Extraction.
- Text Classification.
The pattern underneath all of these is the same: if I have information in the form of natural language, can I use it to solve a business problem? That's the question.
❌ Myth: "NLP is chatbots." ✅ Reality: Chatbots are one layer. NLP is the whole stack — from "where do words start?" up to "what is this person actually trying to tell me?" If you only think of chatbots, you miss 80% of the field.
The restaurant menu insight
Here's the example that made all of this click for me.

Some researchers downloaded thousands of restaurant menus and ran NLP over them. What they found:
- When you go to an expensive restaurant, the menu basically tells you: "give us the control." You sit down, you trust, you let the chef decide. Often there's only one menu.
- Expensive places have half as many dishes as cheap places.
- They're 3× less likely to talk about the diner's choice, and 7× more likely to talk about the chef's choice.
- Longer words in food descriptions correlate with higher prices — about 18 cents more for every additional letter.
- Linguistic fillers — "fresh, crispy, tasty" — show up in cheap restaurants. In an expensive place, they don't need to remind you the food is fresh. It is.
None of that is a model prediction. It's just signal that was sitting in the text the whole time, waiting for someone to extract it. If you want your cheap restaurant to look more expensive — this is the kind of thing NLP lets you do.
That's the part to remember: understanding natural language is what lets you do all the other things. Communication is one use case. Insight is the bigger one.
Where NLP actually sits
People ask: is NLP machine learning? Is it a set of rules? Is it linguistics?
The honest answer:
💡 NLP = Artificial Intelligence + Computational Linguistics.
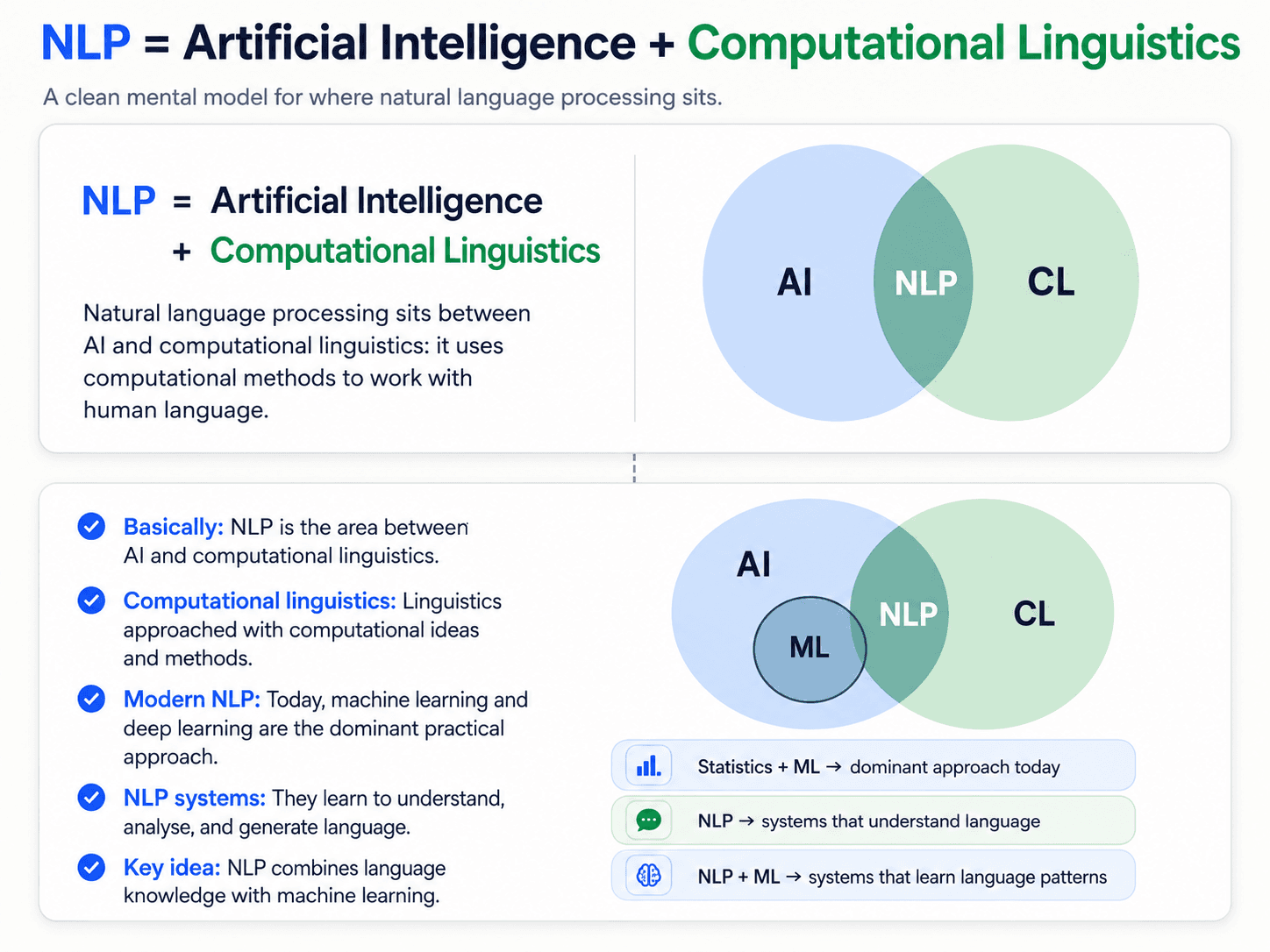
- Computational Linguistics is linguistics using the ideas of computer science. In the past, linguists did everything manually — trying to figure out by hand what makes a sentence work, what the basic structure of a language is. In the 60s, they realised they could do it better with code. Same field, new tools.
- AI isn't the old "fancy name for logistic regression" thing. Machine Learning and Deep Learning are subareas of AI. So NLP = ML/Deep Learning + Computational Linguistics.
Two quick distinctions that matter:
- NLP — systems that understand language.
- NLP × ML — systems that learn how to understand language.
Statistics and ML are the predominant approach today, but they're not the only one. We'll come back to that.
Scope of this series
Three things normally happen with language: you capture it (speech recognition, OCR), you process it (NLP), and you output it (text-to-speech, generation).
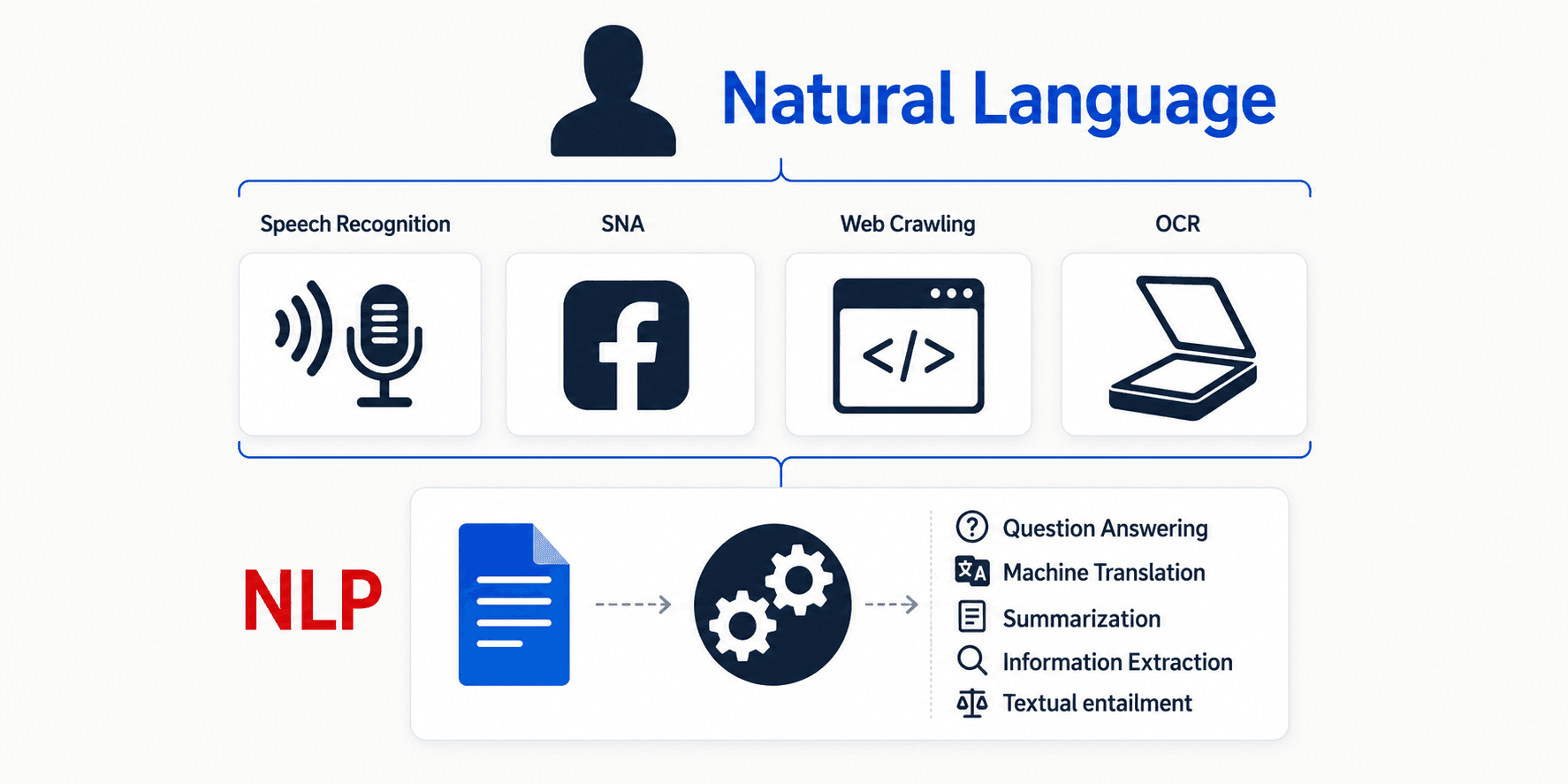
This series focuses on the middle one — processing. We assume the data is already collected. Collection is an engineering problem; processing is where the actual NLP problem lives.
So the question becomes: how do you do NLP? What are the steps? And that brings us to the spine of the entire field — the 5 levels.
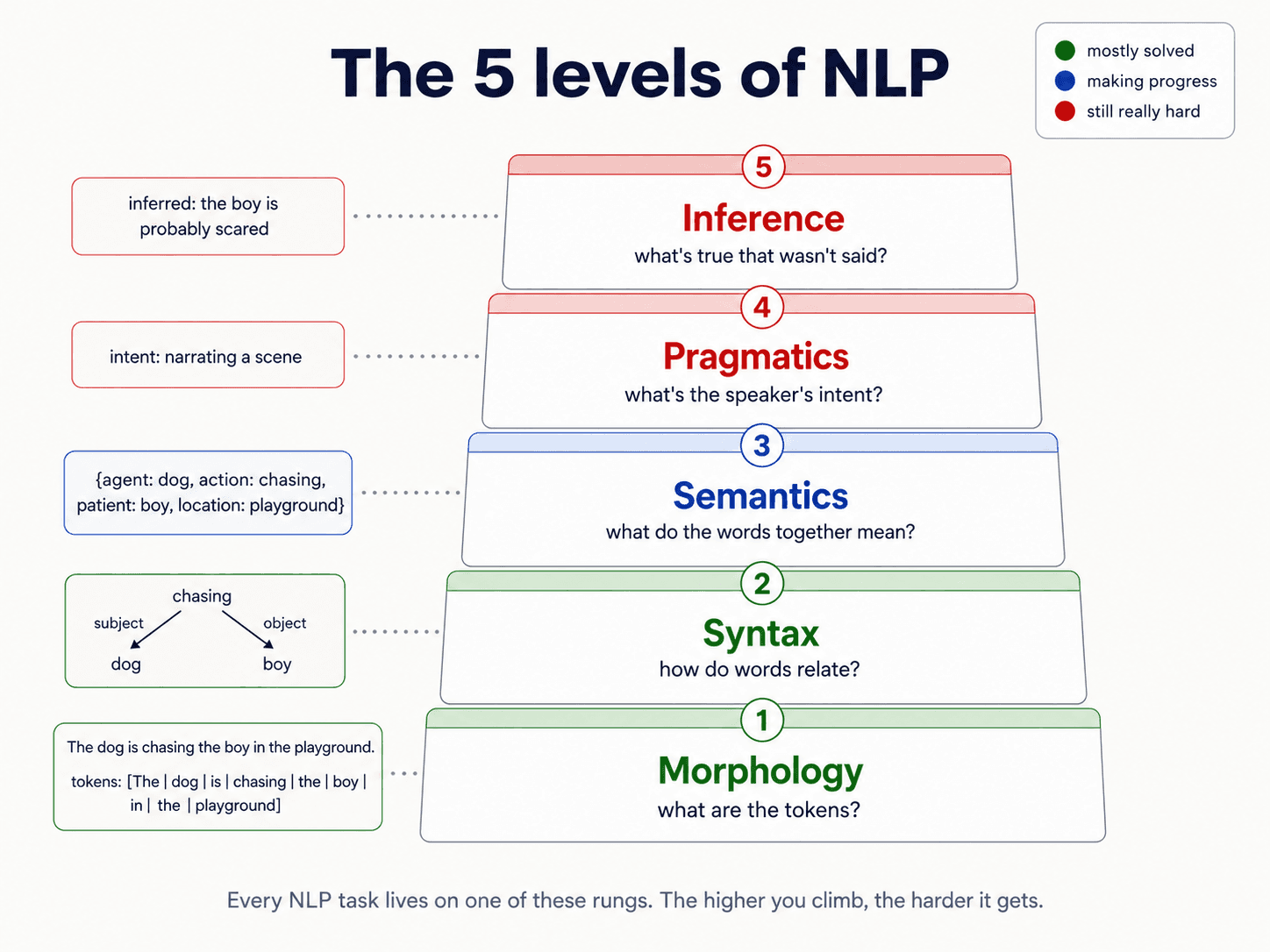
The 5 levels of NLP
A computer sees a sentence as a string — a sequence of characters. To make sense of it, the computer has to climb a ladder. Each rung is a different kind of question.
Here's how the same idea was drawn in the lecture notes I worked from — same 5 levels, slightly different naming convention (some textbooks put Inference at level 4 and Pragmatics at level 5; both orderings are common):
Let's walk it.
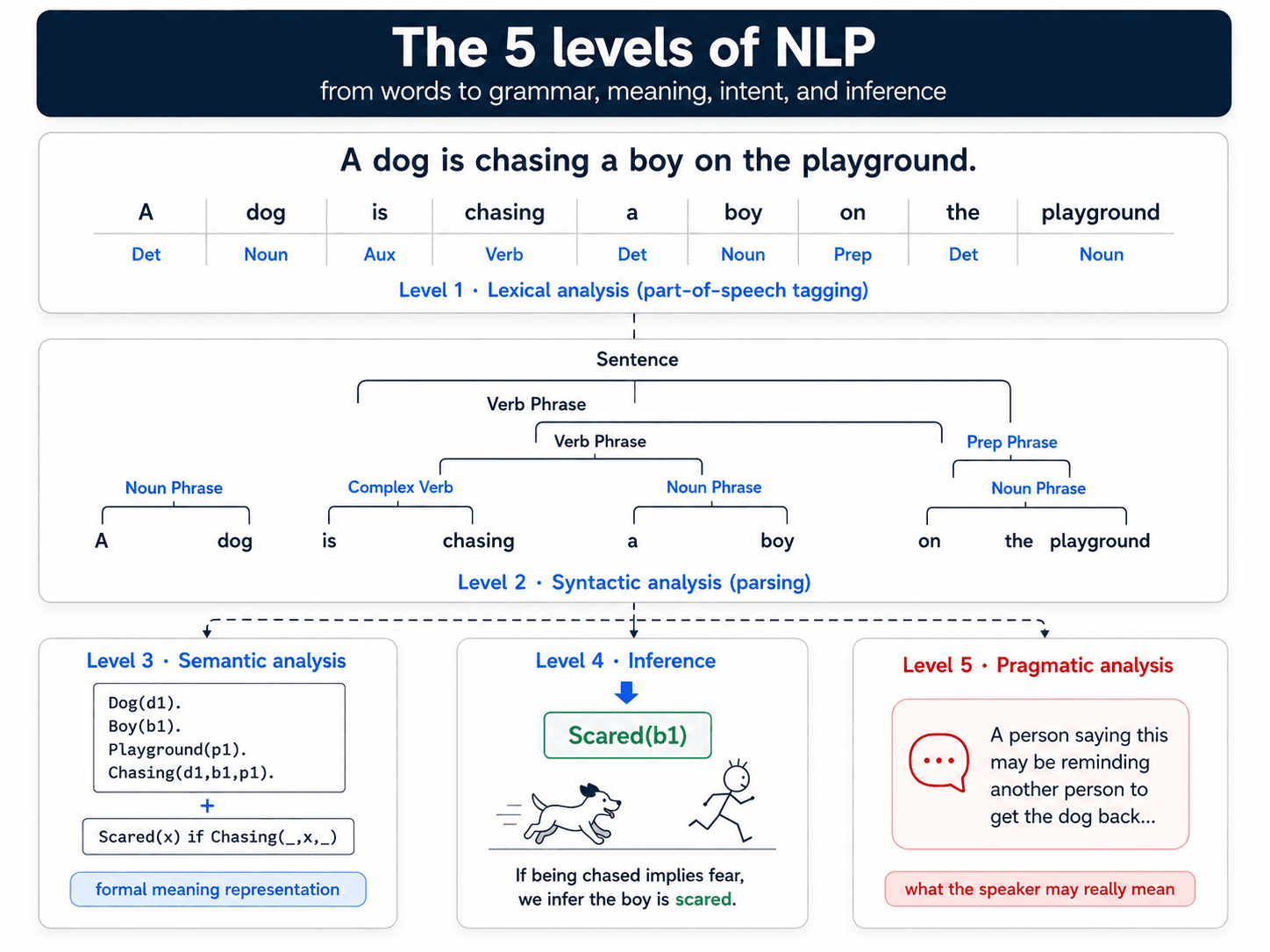
Level 1 — Morphology: what are the tokens?
Before a computer can do anything with a sentence, it has to split it into units of meaning — basically, what counts as a word.
In English, this looks trivial: you split on whitespace, you're mostly done. "The dog is chasing the boy" → ["The", "dog", "is", "chasing", "the", "boy"]. Easy.
It is not easy in other languages. Japanese, for example, doesn't put spaces between words. Korean, Chinese, Thai — same story. Even in English, things like contractions (don't → do + n't?), possessives (Maria's → Maria + 's?), and hyphenated compounds get weird fast.
![A clean instructional diagram in dark navy on a white background, minimal blog style. Title at the top: 'Level 1 — Morphology · what are the tokens?'. Three side-by-side cards. Card 1 'English (easy)' shows the sentence 'The dog is chasing the boy.' with vertical dashed slate-blue dividers between each word, producing tokens [The | dog | is | chasing | the | boy]. A green pill at the bottom of the card reads 'split on whitespace'. Card 2 'Japanese (hard)' shows the sentence '犬が男の子を追いかけている。' as one solid string with no separators, then below it a question mark inside a red circle, and a red pill labeled 'no spaces — where do words start?'. Card 3 'English (the gotchas)' shows three small examples: 'don't → do + n't', 'Maria's → Maria + 's', 'state-of-the-art → ?', each with a red question mark next to it; pill at the bottom in amber: 'contractions, possessives, hyphens'. Caption at the bottom in faint slate-blue: 'Tokenization looks easy until you leave English.'](/_next/image?url=%2Fimages%2Fblog%2Fnlp-from-scratch%2Fintroduction%2Flevel-1-tokens.png&w=3840&q=75)
So even on the easy rung, the easy rung isn't actually that easy. We'll spend a whole session on this in Part 2.
Level 2 — Syntax: how do the words relate?
Next question: now that you have the words, how do they connect?
This is dependency parsing. You're building the grammatical skeleton: who is the subject, who is the object, which verb modifies which noun. "The dog is chasing the boy" — dog is the subject of chasing, boy is the object, the modifies each of them.
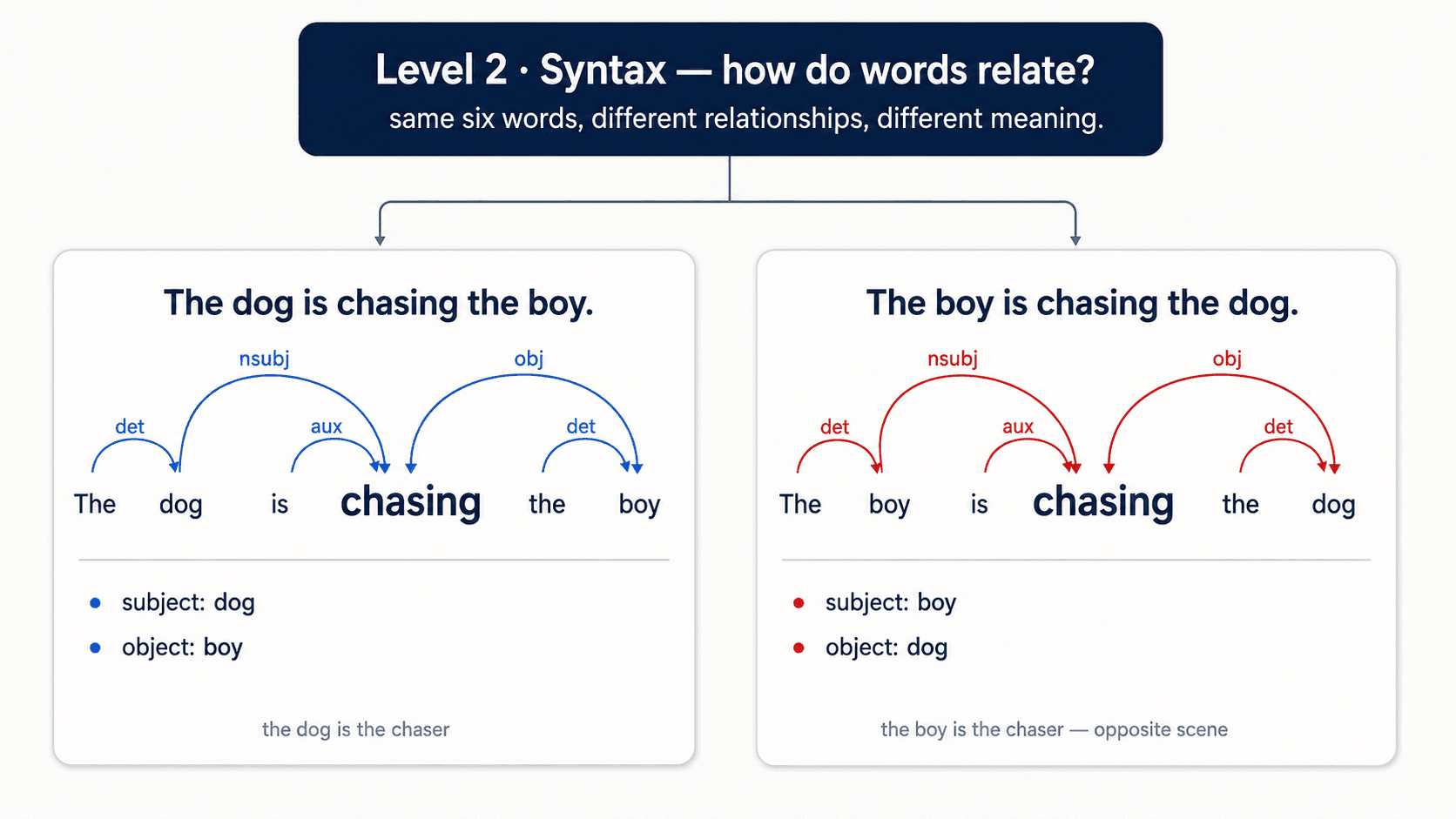
Why this matters: the relationship changes the meaning. "The dog chased the boy" and "The boy chased the dog" contain the exact same six words. Different syntax, completely different scene.
You can't do level 3 without level 2.
Level 3 — Semantics: what does it all mean?
Once you have the tokens and the structure, you can ask: what do these words, together, mean?
This is where things start getting genuinely hard. Words have multiple meanings (a bank is either money or a river edge — only context decides). Sentences have structural ambiguity. And meaning depends on more than just the words on the page — it depends on what's been said before, what's being referred to, what's implied.
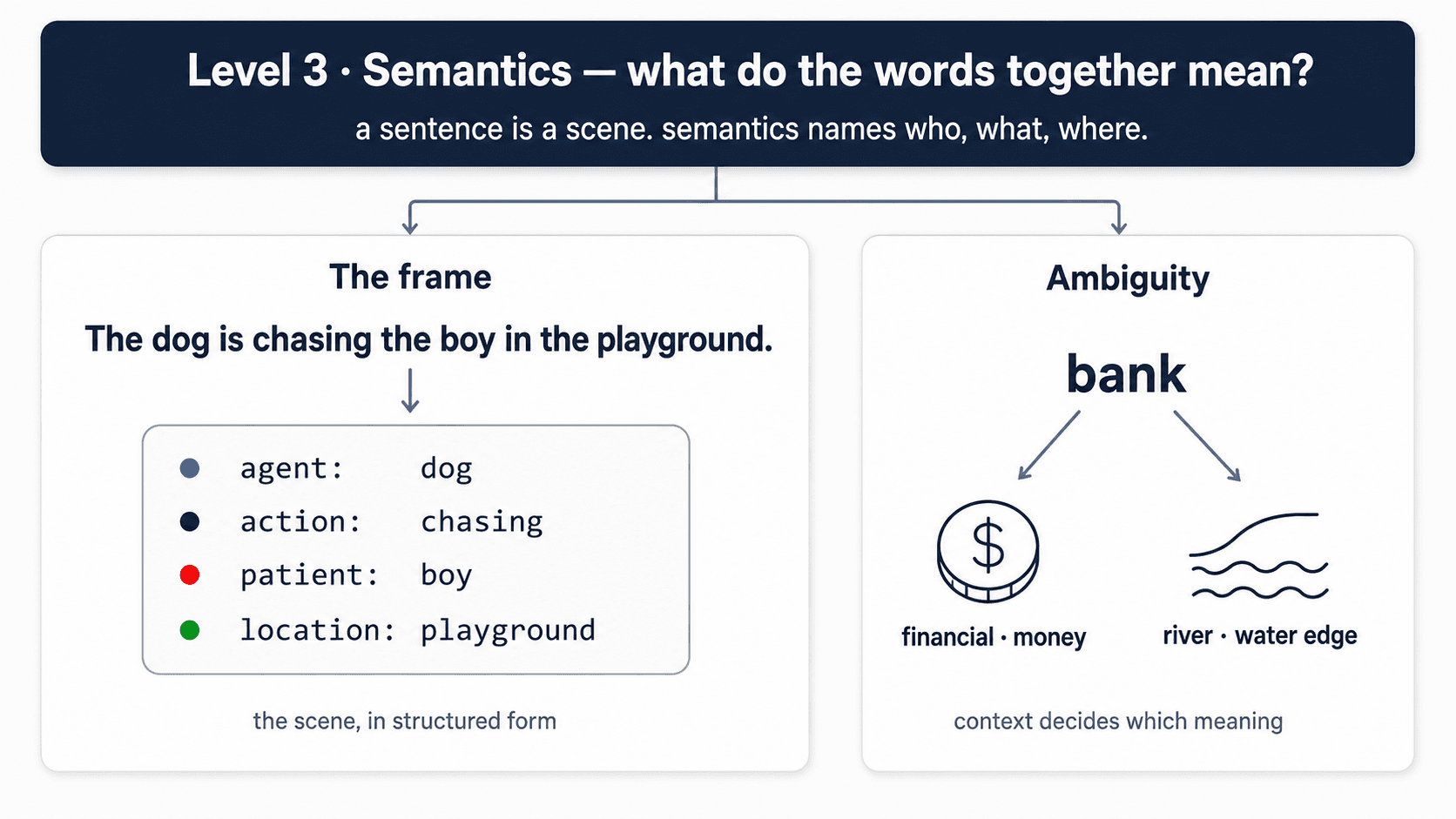
Most modern language models — embeddings, transformers, the whole BERT family — are basically attempts to crack this level. That's why semantics is making good progress but not solved.
Level 4 — Pragmatics: what's the speaker actually trying to do?
The same sentence can mean very different things depending on the speaker's intent.
"Can you pass the salt?" is technically a yes/no question about your physical ability. In practice, it's a request. Saying "yes" and not passing the salt is a joke or a misunderstanding — the literal meaning isn't the intended meaning.
This is what chatbots are wrestling with. When you talk to a customer-service bot, the bot is trying to figure out what you actually want — not just parse the words you typed.
(Even humans take years to get good at this. A two-year-old can technically speak — but reading intent, irony, sarcasm, indirect requests? That takes another decade. It's the kind of skill that genuinely takes a lifetime to master.)
Level 5 — Inference: what's true that wasn't said?
The hardest level. Creating information that was never in the original sentence.
"The dog is chasing the boy in the playground." What do you know that the sentence didn't say?
You know the boy is probably scared.
How? Because you have experience. Maybe a dog chased you once. Or you've seen kids panic at the sight of a strange animal. You're using world knowledge that lives nowhere in those eleven words.
A computer doesn't have that experience. It has the sentence. So inferring new information — the thing humans do constantly, the thing that makes us seem intelligent — is exactly where current NLP systems are failing.
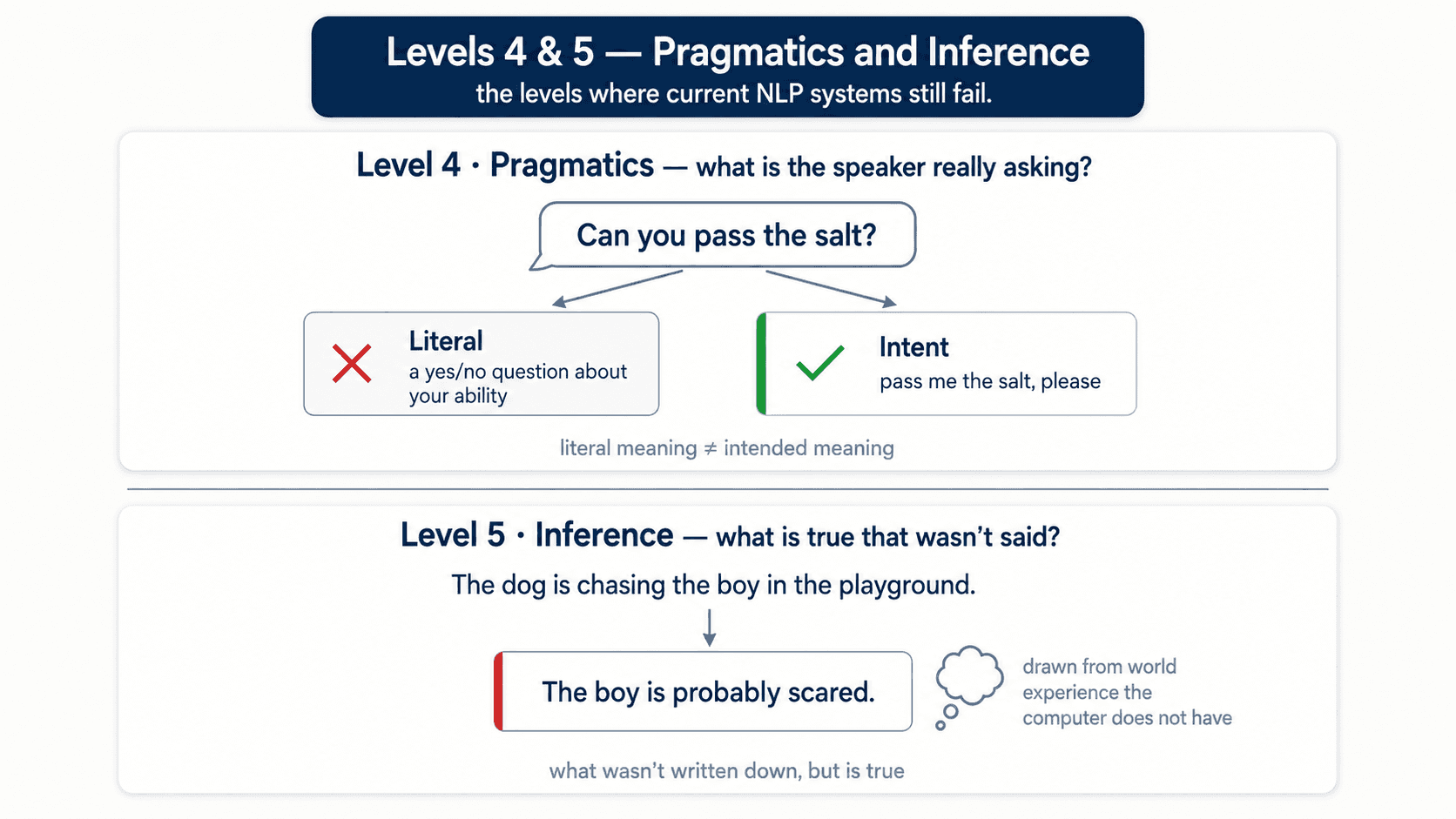
This is what we're really trying to solve. Make the system reason about things that aren't written down.
💡 The BERT example. BERT — one of the most famous NLP models, built by Google — was trained in 2018. So if you ask BERT about COVID, it doesn't know what COVID is. The pandemic happened after its training data ended. BERT can't update its world model the way you can. It can't infer new information from new context. That's the inference problem in one example.
Why NLP is hard (or: why language is built against us)
Language has evolved to be efficient for humans. That same efficiency is what makes it brutal for computers.
Three reasons:
- We omit a lot of common-sense knowledge. If I say "help me with the window" — do I mean open it? Close it? Clean it? Repair it? You'd know from context, room temperature, what we'd been talking about. A computer doesn't have any of that.
- Language is infinitely productive. You can say new things that have never been said before — a combinatorial explosion of possible sentences. You can't memorise a list. The model has to generalise to sentences it has never seen, which is exactly the hard part of any ML problem.
- Ambiguity is the killer. "I saw the man with the telescope." Did I use a telescope to see him, or did I see a man who was holding one? Both readings are valid. Humans pick the right one from context — usually without noticing there was an ambiguity at all.
Most of the data your NLP system will encounter in production is not in its training set. That's not a bug. That's the whole point of language.
The fry-an-egg problem
Imagine you have to explain how to fry an egg. Easy, right? You crack the egg, pour it on the pan, wait.
Now imagine you have to explain it to someone who has never seen an egg or a frying pan. Suddenly you need to explain what an egg is. What a pan is. What "crack" means in this context. What heat is. What "done" looks like.
For a computer, it's worse — the computer doesn't even share the language you're trying to explain things in. You'd have to explain "egg" with a sentence — and that sentence is made of more words the computer also doesn't ground in anything.
This is the problem that pre-trained models and transfer learning were invented to solve. Instead of teaching the model what an egg is from scratch every time, you start from a model that already has a lot of world knowledge baked in (from being trained on huge amounts of text), and you specialise it for your task.
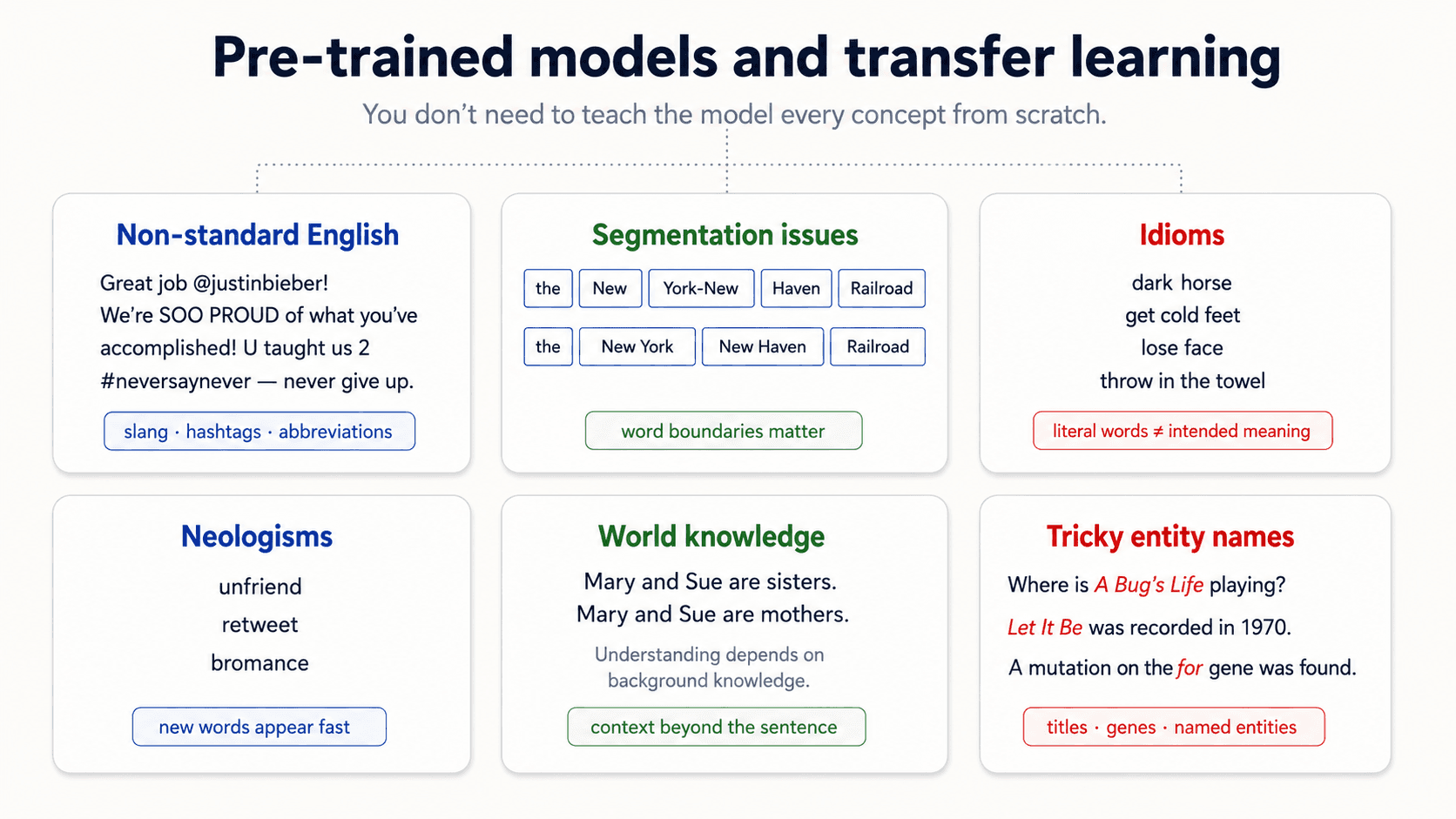
We'll come back to this in a later session — but it's the reason 2018 onwards has been such a leap forward.
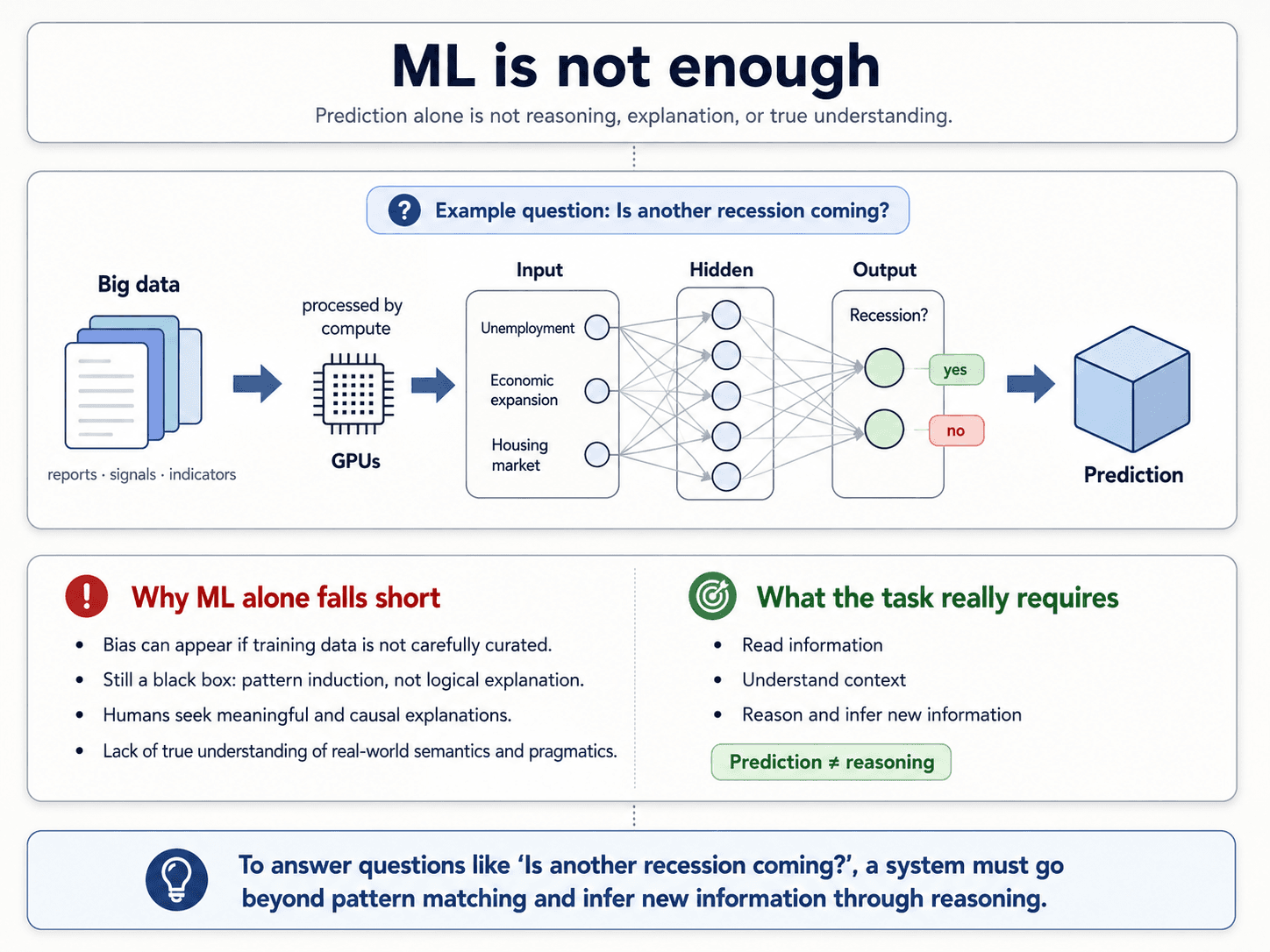
Is statistics + ML enough?
Most modern NLP is "give me a big enough dataset and I'll learn anything." It works shockingly well for a lot of tasks. But it has cracks:
- Bias — if your training corpus isn't curated, the model inherits whatever bias is in the data. Sometimes amplifies it.
- Black box — the model gives you an answer, not an explanation. It's pure induction — pattern-matching at scale, not logical reasoning.
- Humans want causal explanations. "It's correlated with this" isn't the same as "this caused that." NLP models don't really do "because."
- No true grounding in real-world semantics or pragmatics. The model has read about coffee but has never tasted it.
The honest take: ML alone is not enough.
Concrete example. Say you have a stack of economic reports and someone asks: "is another recession coming?" You have to read the reports, understand them, reason across them, and produce new information — an inference — that wasn't in any single report. That kind of reasoning over text is exactly where current models still struggle.
The knowledge-based approach (and the pendulum)
The opposite bet. IBM Watson is the classic example.
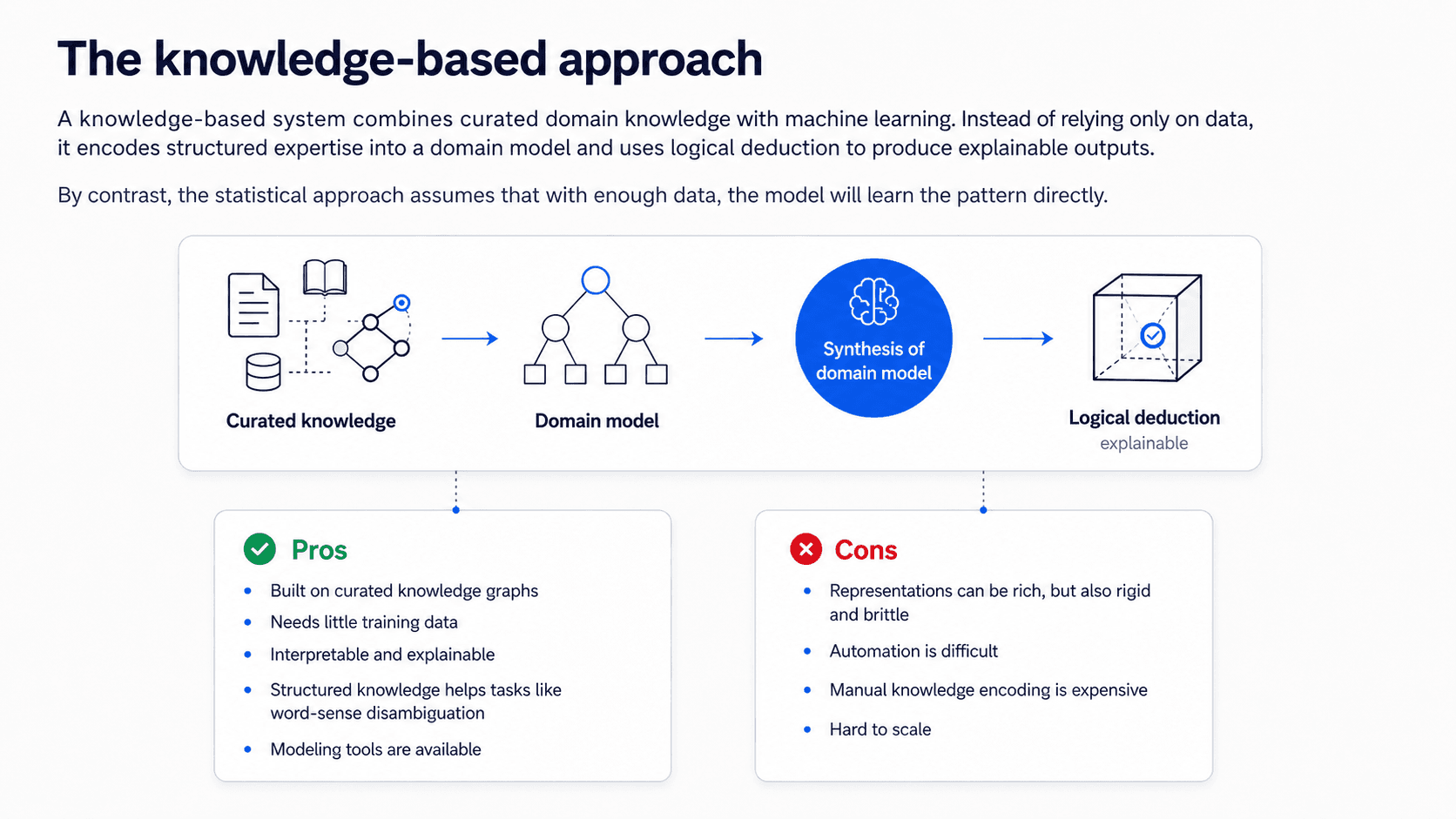
For a long time this was on top and statistics was the underdog. Then deep learning arrived and the pendulum swung hard the other way. We're at the peak of the statistics wave now — transformers, large language models, the whole party. Knowledge-based work is quieter, but the pendulum has swung before.
❌ Myth: "If you have a linguist on your team and you fire them, model performance goes up 10%." (Yes, this is a real NLP joke.) ✅ Reality: Deep learning is the most advanced way to do NLP — but it's still a black box, and the pendulum has swung knowledge ↔ statistics ↔ knowledge before. The cognitive chasm — the gap between predicting patterns in text and actually understanding language — is still wide open. Don't fire the linguist.
Where the field actually is right now
The honest snapshot, mapped against the 5 levels above:
- ✅ Mostly solved. Preprocessing at the morphological and lexical level. Simple classification tasks (spam vs not-spam, sentiment as positive/negative).
- 🟡 Making good progress. Preprocessing at the semantic level. Advanced text classification (multi-label, fine-grained sentiment, intent detection). Machine translation between high-resource languages.
- 🔴 Still really hard. Tasks at the pragmatic and inference levels. True dialogue. Long-form reasoning. Anything that requires the model to know something it wasn't told.
This is why the pyramid is colour-coded the way it is. The bottom of the ladder is largely solved engineering. The top is open research.
Why NLP, and why now?
A few practical reasons companies care:
- Improve user experience. Smart search, voice assistants, better autocomplete.
- Automate support. Triage tickets, route complaints, answer the easy 80%.
- Monitor and analyse feedback. Reviews, social, internal surveys — text data at a scale no human team can read by hand.
The big players — Google, Meta, Microsoft, OpenAI, Anthropic — are all betting heavily on language understanding as the next interface. Talking to your computer has gone from "60s science fiction" to "what most people did this morning."
The cognitive chasm
The aspiration in the background of all this — sometimes called the Adam Tuning aspiration — is: create real intelligence. And you basically can't get there without NLP, because language is the way intelligence gets expressed.
But there's a gap. Some open questions that nobody has fully answered:
- How do we merge human understanding and machine understanding?
- Are they cognitively disconnected — are we and the model actually doing different things?
- If they are different, what mechanisms would cross the chasm?
- How should knowledge be represented — in a way that's flexible, scalable, deep, and logically consistent?
I don't have answers to these. Nobody does yet. They're the reason the field is still interesting.
What's next
Now we have the map. Every future post in this series picks one rung on the ladder and goes deep:
- Part 2 — Morphology and basic text processing. How does a computer split "The dog is chasing the boy" into tokens? And why does Japanese, with no spaces between words, break every assumption we made in this post?
- Part 3 — Syntax: tagging and parsing. Turning a token sequence into a dependency tree.
- Part 4 — Semantics. Word meaning, embeddings, the leap from symbols to vectors.
- Part 5 — Text classification. The first place where everything we've built starts paying off.
- Part 6 — Language modelling, IR, QA. The path toward systems that don't just classify text, but generate and retrieve it.
This series is going to build the same way the ML series did — one rung at a time, every concept connecting to the next. The pyramid is the map. Keep it nearby.
See you in Part 2.